Posts from October, 2008
October 20, 2008
Chip and Randy @ Living Game Worlds IV 12/1-12/2
Registration is now open for
Living Game Worlds IV – Interplay: Multiplayer Games and Virtual Worlds
December 1-2, 2008
Georgia Tech
Technology Square Research Building
85 5th Street, Atlanta, GA
Step in to the vanguard of digital gaming at Georgia Tech’s 4th annual Living Game Worlds symposium to be held December 1-2, 2008. Raph Koster and Chris Klaus headline this year’s conference which will showcase “InterPlay,” networked online play and the rapidly-growing domains of multiplayer games and virtual worlds. The symposium will also feature a pioneers panel including luminaries Richard Bartle, Brian Green, Chip Morningstar, Randy Farmer and Pavel Curtis. Also, don’t miss the chance to see the latest demos from Georgia Tech’s Digital Media Program, EGL, and GVU. Early registration ends October 31. Register now at http://gameworlds.gatech.edu
Media Inquiries: gameworlds-media@lists.gatech.edu
All other Inquiries: gameworlds@lists.gatech.edu
[Please Circulate]
October 17, 2008
The Tripartite Identity Pattern
One of the most misunderstood patterns in social media design is that of user identity management. Product designers often confuse the many different roles required by various user identifiers. This confusion is compounded by using older online services, such as Yahoo!, eBay and America Online, as canonical references. The services established their identity models based on engineering-centric requirements long before we had a more subtle understanding of user requirements for social media. By conjoining the requirements of engineering (establishing sessions, retrieving database records, etc.) with the users requirements of recognizability and self-expression, many older identity models actually discourage user participation. For example: Yahoo! found that users consistently listed that the fear of spammers farming their e-mail address was the number one reason they gave for abandoning the creation of user created content, such as restaurant reviews and message board postings. This ultimately led to a very expensive and radical re-engineering of the Yahoo identity model which has been underway since 2006.
Consistently I’ve found that a tripartite identity model best fits most online services and should be forward compatible with current identity sharing methods and future proposals.
The three components of user identity are: the account identifier, the login identifier, and the public identifier.
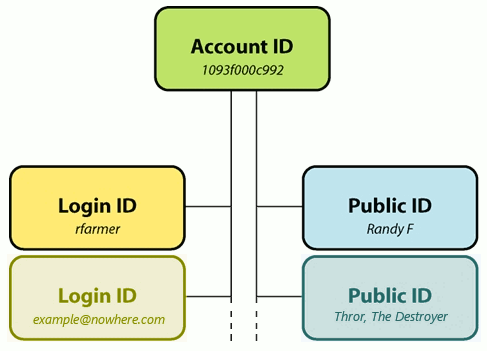
Account Identifier (DB Key)
From an engineering point of view, there is always one database key – one-way to access a user’s record – one-way to refer to them in cookies and potentially in URLs. In a real sense he account identifier is the closest thing the company has to a user. It is required to be unique and permanent. Typically this is represented by a very large random number and is not under the user’s control in any way. In fact, from the user’s point of view this identifier should be invisible or at the very least inert; there should be no inherent public capabilities associated with this identifier. For example it should not be an e-mail address, accepted as a login name, displayed as a public name, or an instant messenger address.
Login Identifier(s) (Session Authentication)
Login identifiers are necessary create valid sessions associated with an account identifier. They are the user’s method of granting access to his privileged information on the service. Historically, these are represented by unique and validated name/password pairs. Note that the service need not generate its own unique namespace for login identifiers but may adopt identifiers from other providers. For example, many services except external e-mail addresses as login identifiers usually after verifying that the user is in control of that address. Increasingly, more sophisticated capability-based identities are accepted from services such as OpenID, oAuth, and Facebook Connect; these provide login credentials without constantly asking a user for their name and password.
By separating the login identifier from the account identifier, it is much easier to allow the user to customize their login as the situation changes. Since the account identifier need never change, data migration issues are mitigated. Likewise, separating the login identifier from public identifiers protects the user from those who would crack their accounts. Lastly, a service could provide the opportunity to attach multiple different login identifiers to a single account — thus allowing the service to aggregate information gathered from multiple identity suppliers.
Public identifier(s) (Social Identity)
Unlike the service-required account and login identifiers, the public identifier represents how the user wishes to be perceived by other users on the service. Think of it like clothing or the familar name people know you by. By definition, it does not possess the technical requirement to be 100% unique. There are many John Smiths of the world, thousands of them on Amazon.com, hundreds of them write reviews and everything seems to work out fine.
Online a user’s public identifier is usually a compound object: a photo, a nickname, and perhaps age, gender, and location. It provides sufficient information for any viewer to quickly interpret personal context. Public identifiers are usually linked to a detailed user profile, where further identity differentiation is available; ‘Is this the same John Smith from New York that also wrote the review of the great Gatsby that I like so much?’ ‘Is this the Mary Jones I went to college with?’
A sufficiently diverse service, such as Yahoo!, may wish to offer multiple public identifiers when a specific context requires it. For example, when playing wild-west poker a user may wish to present the public identity of a rough-and-tumble outlaw, or a saloon girl without having that imagery associated with their movie reviews.
Update 11/12/2008: This model was presented yesterday at the Internet Identity Workshop as an answer to many of the confusion surrounding making the distributed identity experience easier for users. The key insight this model provides is that no publicly shared identifier is required (or even desirable) to be used for session authentication, in fact requiring the user to enter one on a RP website is an unnecessary security risk.
Three main critiques of the model were raised that should be addressed in a wider forum:
- There was some confusion of the scope of the model – Are the Account IDs global?
I hand modified the diagram to add an encompassing circle to show the context is local – a single context/site/RP. In a few days I’ll modify the image in this post to reflect the change.
- The term “Public Identity” is already in use by iCards to mean something incompatible with this model.
I am more than open to an alternative term that captures this concept. Leave comments or contact me at randy dot farmer at pobox dot com.
- Publically sharable capability-based identifiers are not included in this model. These include email addresses, easy-to-read-URLs, cel phone numbers etc.
There was much controversy on this point. To me, these capability based identifiers are outside the scope of the model, and generating them and policies sharing them are withing the scope of the context/site/RP. Perhaps an interested party might adopt the tripartite pattern as a sub-pattern of a bigger sea of identifiers. My goal was not to be all encompassing, but to demonstrate that only three identifiers are required for sites that have user generated content, and that no public capability bound ID exchange was required. RPs should only see a the Public ID and some unique key for the session that grants permission bound access to the user’s Account.
October 14, 2008
Context is King: Lessons from Online Communities
Here’s the SlideShare from the talk I’m giving tonight at BayChi. This is the first time I’m presenting this information to the general public. If you can make it, I can only say that the notes I uploaded with the deck are complete, but are really only a guideline to what I might say live – every presentation is different.
If you’ve come here after the presentation, please feel free to comment on this post as an alternate feedback channel.
When the video is available, I’ll update this post with the pointer and share the presentation more widely.