October 17, 2008
The Tripartite Identity Pattern
One of the most misunderstood patterns in social media design is that of user identity management. Product designers often confuse the many different roles required by various user identifiers. This confusion is compounded by using older online services, such as Yahoo!, eBay and America Online, as canonical references. The services established their identity models based on engineering-centric requirements long before we had a more subtle understanding of user requirements for social media. By conjoining the requirements of engineering (establishing sessions, retrieving database records, etc.) with the users requirements of recognizability and self-expression, many older identity models actually discourage user participation. For example: Yahoo! found that users consistently listed that the fear of spammers farming their e-mail address was the number one reason they gave for abandoning the creation of user created content, such as restaurant reviews and message board postings. This ultimately led to a very expensive and radical re-engineering of the Yahoo identity model which has been underway since 2006.
Consistently I’ve found that a tripartite identity model best fits most online services and should be forward compatible with current identity sharing methods and future proposals.
The three components of user identity are: the account identifier, the login identifier, and the public identifier.
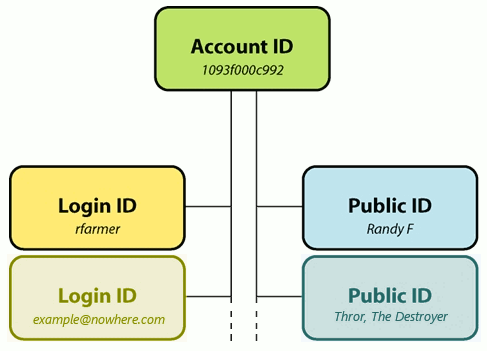
Account Identifier (DB Key)
From an engineering point of view, there is always one database key – one-way to access a user’s record – one-way to refer to them in cookies and potentially in URLs. In a real sense he account identifier is the closest thing the company has to a user. It is required to be unique and permanent. Typically this is represented by a very large random number and is not under the user’s control in any way. In fact, from the user’s point of view this identifier should be invisible or at the very least inert; there should be no inherent public capabilities associated with this identifier. For example it should not be an e-mail address, accepted as a login name, displayed as a public name, or an instant messenger address.
Login Identifier(s) (Session Authentication)
Login identifiers are necessary create valid sessions associated with an account identifier. They are the user’s method of granting access to his privileged information on the service. Historically, these are represented by unique and validated name/password pairs. Note that the service need not generate its own unique namespace for login identifiers but may adopt identifiers from other providers. For example, many services except external e-mail addresses as login identifiers usually after verifying that the user is in control of that address. Increasingly, more sophisticated capability-based identities are accepted from services such as OpenID, oAuth, and Facebook Connect; these provide login credentials without constantly asking a user for their name and password.
By separating the login identifier from the account identifier, it is much easier to allow the user to customize their login as the situation changes. Since the account identifier need never change, data migration issues are mitigated. Likewise, separating the login identifier from public identifiers protects the user from those who would crack their accounts. Lastly, a service could provide the opportunity to attach multiple different login identifiers to a single account — thus allowing the service to aggregate information gathered from multiple identity suppliers.
Public identifier(s) (Social Identity)
Unlike the service-required account and login identifiers, the public identifier represents how the user wishes to be perceived by other users on the service. Think of it like clothing or the familar name people know you by. By definition, it does not possess the technical requirement to be 100% unique. There are many John Smiths of the world, thousands of them on Amazon.com, hundreds of them write reviews and everything seems to work out fine.
Online a user’s public identifier is usually a compound object: a photo, a nickname, and perhaps age, gender, and location. It provides sufficient information for any viewer to quickly interpret personal context. Public identifiers are usually linked to a detailed user profile, where further identity differentiation is available; ‘Is this the same John Smith from New York that also wrote the review of the great Gatsby that I like so much?’ ‘Is this the Mary Jones I went to college with?’
A sufficiently diverse service, such as Yahoo!, may wish to offer multiple public identifiers when a specific context requires it. For example, when playing wild-west poker a user may wish to present the public identity of a rough-and-tumble outlaw, or a saloon girl without having that imagery associated with their movie reviews.
Update 11/12/2008: This model was presented yesterday at the Internet Identity Workshop as an answer to many of the confusion surrounding making the distributed identity experience easier for users. The key insight this model provides is that no publicly shared identifier is required (or even desirable) to be used for session authentication, in fact requiring the user to enter one on a RP website is an unnecessary security risk.
Three main critiques of the model were raised that should be addressed in a wider forum:
- There was some confusion of the scope of the model – Are the Account IDs global?
I hand modified the diagram to add an encompassing circle to show the context is local – a single context/site/RP. In a few days I’ll modify the image in this post to reflect the change.
- The term “Public Identity” is already in use by iCards to mean something incompatible with this model.
I am more than open to an alternative term that captures this concept. Leave comments or contact me at randy dot farmer at pobox dot com.
- Publically sharable capability-based identifiers are not included in this model. These include email addresses, easy-to-read-URLs, cel phone numbers etc.
There was much controversy on this point. To me, these capability based identifiers are outside the scope of the model, and generating them and policies sharing them are withing the scope of the context/site/RP. Perhaps an interested party might adopt the tripartite pattern as a sub-pattern of a bigger sea of identifiers. My goal was not to be all encompassing, but to demonstrate that only three identifiers are required for sites that have user generated content, and that no public capability bound ID exchange was required. RPs should only see a the Public ID and some unique key for the session that grants permission bound access to the user’s Account.
Hi Randy,
Two observations:
1. There could be multiple login IDs associated with an account ID, right? This would allow services or users to easily reuse external authentication services (OpenID) but not be locked in to them. This also facilitates mergers of different services into the same user pool (due to acquisition, service redesign, etc.)
There could also be multiple public IDs, used in different contexts.
2. Should the account ID never be shown publicly? If the only publicly shown identifier is the user-controlled public ID, then it’s easy for trolls etc to manipulate what others think their identity is. (Though different communities will have different needs here and different weights for this potential problem.)
Posted by: Reed Hedges | October 18, 2008, 4:47 am
Reed,
Glad you liked the post. It may be short, but folds in almost 5 years of refinement and insight.
1. I agree, as I said in the post above “Lastly, a service could provide the opportunity to attach multiple different login identifiers to a single account” and also “A … service… may wish to offer multiple public identifiers when a specific context requires”
2. Actually, the Account ID is a key that can be shared for API use, hashed for URLs, etc. as long as it has no inherent capabilities. Spoofing is a minor threat, and the account ID could be used to differentiate without displaying it.
For example if two folks with the public ID James (and the same photo, age, location, etc.) post to a forum, the page display logic could differentiate them as James(1) and James(2) consistently.
Of course, the community might have something to say about anyone who is trying to spoof another person.
Posted by: F. Randall Farmer | October 18, 2008, 9:16 am
Reed’s scanning error was common when I first published this model inside of Yahoo! I was in a hurry to post the article in time for an upcoming identity standards related event and used an accurate, but perhaps oversimplified,image.
This has been corrected.
Now if you only look at the picture instead of reading the text completely, you’ll be able to see that the pattern supports multiple Login IDs and Public IDs.
Posted by: F. Randall Farmer | October 18, 2008, 10:27 am
Thanks, the changed image makes it much clearer. I wasn’t sure if you meant that there could simultaneously be more than one ID, or whether there were multiple options for what form that ID could take.
I would make the internal account ID be either completely private (so you can change it someday if needed), or give it some globally unique property (i.e. based on a URI or a GUID or whatever) (so you wouldn’t have to change it).
For public APIs, you can generate a key or id from the account ID, specifically for the user to give to another application that is going to use the API. You can generate a new key like this for each third party service, which would also allow the user to disable them selectively or set different access options for each of them. So this would be a third branch of external identifiers.
Posted by: Reed | October 20, 2008, 6:33 am
This seems to map quite well to the account element in PortableContacs/OpenSocial/SGNodeMapper where username and userid are used for the two parts you call Login ID and Account ID, and displayName is used for what you call Public ID
http://portablecontacts.net/draft-spec.html#account_element
Posted by: Kevin Marks | November 11, 2008, 5:39 pm
Thanks Kevin! I’ll try to corner Joseph when I see him later today.
Posted by: F. Randall Farmer | November 12, 2008, 8:01 am
So I can trust my identity morph to you or manage it myself, right?
Posted by: Orthomentor | March 4, 2010, 1:22 pm
It’s wrong to say that spoofing is a small problem. In aggregate it may be, but if you’re user being spoofed, it’s a huge problem. If you look at most of Yahoo!’s blogs, it’s trivial to impersonate the writer of a post because it’s so easy to change one’s Core ID nickname. Coloring a blogger’s posts Green and the spoofer’s post Red does nothing to solve the problem because the a third party will not know the pattern used for each. Only if a site (like Y! Sports) uses a special demarcation reserved for Authors can users really know who is who. And for individual users, all hope is lost if someone starts acting like someone else.
This tripartite identity model as implemented at Y! took something real (YID’s) and replaced it with something easily fungible and encouraged users to change it on a whim. It encouraged replacing one handle with another that much worse. This was the absolute wrong approach. It created a world of anonymous users with no ability to prevent spoofing nor encouraged users to invest in their identity. One example was my fantasy leagues. I had gotten to know users by their YID’s, and core id ruined this experience. Who a user was could change at a whim, and even playing among close friends, I often don’t know who is who. A suggestion to remedy this problem was to create property specific nicknames that could not be easily changed and must be unique. This was rejected by the folks implementing this spec.
Facebook comes along two years later and encourages users to publicly identify themselves everywhere, adds a identifying information like initial network, and clamps down on users spoofing other users, and they win the war. That was the approach Yahoo! should have taken. It’s not right to blame slow adoption of this model as the reason Yahoo! failed at social.
Posted by: EJ | December 13, 2010, 1:33 am
EJ,
Thanks for your comment. You raise several issues – many of which have important and subtle arguments.
“It’s wrong to say that spoofing is a small problem.” then you say “In aggregate it may be…” So you understand my context. Then you go on “but if you’re user being spoofed, it’s a huge problem” – that is also true. Though I don’t agree with “it’s trivial to impersonate the writer of a post”, at least I don’t agree by design, if not the actual implementation. In order to explain, I’ll quote from the end of your comment:
“Facebook comes along two years later and encourages users to publicly identify themselves everywhere, adds a identifying information like initial network, and clamps down on users spoofing other users, and they win the war. That was the approach Yahoo! should have taken.” – All I can do is strongly agree with this statement – and Yahoo! was on this path until the abandoned all efforts to unify their social graphs (YIM, Yahoo 360, etc.) – which I explained in the Quora post on this matter. Identity IS context, not a string, unique or not. When Yahoo! stopped caring about building a rich persona/profile behind the user, they lost the war before it started. Note that Facebook lets you change your name “trivially”, but because of deep contextual connections you can tell all the “John Smith”s apart. Facebook names are not unique.
Perhaps you didn’t understand that CoreID was only a part (as described in this post) of the needed steps to build robust identity at Yahoo!, not the entire solution (it was never intended to be.) You should feel free to suggest that an incremental approach to this problem would have never worked (and has some of the problems you detail.) Again, in hindsight, I would agree – but there were no other options, except to give up before we started, I guess.
The one thing we will probably always disagree on is that the use of a users email address, instant messenger id, and 1/2 their login credentials (aka the YID) as a public identifier for user generated content is appropriate in most contexts.
The users told us this over and over. Of this I have no doubts.
Posted by: Randy Farmer | December 13, 2010, 1:38 pm
Thanks for the detailed response :)
Posted by: EJ | December 14, 2010, 2:02 am
This is actually the model used by video game developers when able to make multiple characters. It is my belief that it should (or ‘could’ as extra option) be rejected because it leads to fragmentation in buddy recognition (global minds as we are) with already declining user bases (and there is probably no budget to develop ID-tree-based-buddy-systems). I opt for 1 global public ID as motivator to stick to just one account and save customer s(ervice) alot of account management. Furthermore it can support subscriptions for multi boxing characters or selling character spots. It would save the mess from the perspective of the customer where people make alot of accounts to circumvent account constraints. All in all I would say K.I.S.S. for more good available nicknames (public ID’s) and so less discutable pick(s) thereof due to unavailabilities. Only downside is that gender roleplay could complicate an uniform nickname but this could also make people more tempted to pick their (real) gender(s). But an extra universal buddy identifier could just less well done be an implementation. Although it may have to support multiple accounts which would not be desirable. I am all for going ‘real gender’ because AI already allows us to upload our real body model (for parts thereof like the heads).
Posted by: Bram | February 13, 2018, 1:25 pm