Posts filed under "Theory"
April 13, 2022
Game Governance Domains: a NFT Support Nightmare
“I was working on an online trading-card game in the early days that had player-to-player card trades enabled through our servers. The vast majority of our customer support emails dealt with requests to reverse a trade because of some kind of trade scams. When I saw Hearthstone’s dust system, I realized it was genius; they probably cut their support costs by around 90% with that move alone.”
Ian Schreiber
A Game’s Governance Domain
There have always been key governance requirements for object trading economies in online games, even before user-generated-content enters the picture. I call this the game’s object governance domain.
Typically, an online game object governance domain has the following features (amongst others omitted for brevity):
- There is usually at least one fungible token currency
- There is often a mechanism for player-to-player direct exchange
- There is often one or more automattic markets to exchange between tokens and objects
- May be player to player transactions
- May be operator to player transactions (aka vending and recycling machinery)
- Managed by the game operator
- There is a mechanism for reporting problems/disputes
- There is a mechanism for adjudicating conflicts
- There are mechanisms for resolving a disputes, including:
- Reversing transactions
- Destroying objects
- Minting and distributing objects
- Minting and distributing tokens
- Account, Character, and Legal sanctions
- Rarely: Changes to TOS and Community Guidelines
In short, the economy is entirely in the ultimate control of the game operator. In effect, anything can be “undone” and injured parties can be “made whole” through an entire range of solutions.
Scary Future: Crypto? Where’s Undo?
Introducing blockchain tokens (BTC, for example) means that certain transactions become “irreversible”, since all transactions on the chain are 1) Atomic and 2) Expensive. In contrast, many thousands of credit-card transactions are reversed every minute of every day (accidental double charges, stolen cards, etc.) Having a market to sell an in-game object for BTC will require extending the governance domain to cover very specific rules about what happens when the purchaser has a conflict with a transaction. Are you really going to tell customers “All BTC transactions are final. No refunds. Even if your kid spent the money without permission. Even if someone stole your wallet”?
Nightmare Future: Game UGC & NFTs? Ack!
At least with your own game governance domain, you had complete control over IP presented in your game and some control, or at least influence, over the games economy. But it gets pretty intense to think about objects/resources created by non-employees being purchased/traded on markets outside of your game governance domain.
When your game allows content that was not created within that game’s governance domain, all bets are off when it comes to trying to service customer support calls. And there will be several orders of magnitude more complaints. Look at Twitter, Facebook, and Youtube and all of the mechanisms they need to support IP-related complaints, abuse complaints, and robot-spam content. Huge teams of folks spending millions of dollars in support of Machine Learning are not able to stem the tide. Those companies’ revenue depends primarily on UGC, so that’s what they have to deal with.
NFTs are no help. They don’t come with any governance support whatsoever. They are an unreliable resource pointer. There is no way to make any testable claims about any single attribute of the resource. When they point to media resources (video, jpg, etc.) there is no way to verify that the resource reference is valid or legal in any governance domain. Might as well be whatever someone randomly uploaded to a photo service – oh wait, it is.
NFTs have been stolen, confused, hijacked, phished, rug-pulled, wash-traded, etc. NFT Images (like all internet images) have been copied, flipped, stolen, misappropriated, and explicitly transformed. There is no undo, and there is no governance domain. OpenSea, because they run a market, gets constant complaints when there is a problem, but they can’t reverse anything. So they madly try to “prevent bad listings” and “punish bad accounts” – all closing the barn door after the horse has left. Oh, and now they are blocking IDs/IPs from sanctioned countries.
So, even if a game tries to accept NFT resources into their game – they end up in the same situation as OpenSea – inheriting all the problems of irreversibility, IP abuse, plus new kinds of harassment with no real way to resolve complaints.
Until blockchain tokens have RL-bank-style undo, and decentralized trading systems provide mechanisms for a reasonable standard of governance, online games should probably just stick with what they know: “If we made it, we’ll deal with any governance problems ourselves.”
August 5, 2021
August 28, 2019
The Unum Pattern
Warning: absurd technical geekery ahead — even compared to the kinds of things I normally talk about. Seriously. But things will be back to my normal level of still-pretty-geeky-but-basically-approachable soon enough.
[Historical note: This post has been a long time in the making — the roots of the fundamental idea being described here go back to the original Habitat system (although we didn’t realize it at the time). It describes a software design pattern for distributed objects — which we call the “unum” — that I and some of my co-conspirators at various companies have used to good effect in many different systems, but which is still obscure even among the people who do the kinds of things I do. In particular, I’ve described this stuff in conversation with lots of people over the years and a few of them have published descriptions of what they understood, but their writeups haven’t, to my sensibilities at least, quite captured the idea as I conceive of it. But I’ve only got myself to blame for this as I’ve been lax in actually writing down my own understanding of the idea, for all the usual reasons one has for not getting around to doing things one should be doing.]
Consider a distributed, multi-participant virtual world such as Habitat or one of its myriad descendants. This world is by its nature very object oriented, but not in quite the same way that we mean when we talk about, for example, object oriented programming. This is confusing because the implementation is, itself, very object oriented, in exactly the object oriented programming sense.
Imagine being in this virtual world somewhere, say, in a room in a building in downtown Populopolis. And there is a table in the room and sitting on the table is a teacup. Well, I said you were in the virtual world, but you’re not really in it, your avatar is in it, and you are just interacting with it through the mediation of some kind of client software running on your local computer (or perhaps these days on your phone), which is in turn communicating over a network connection to a server somewhere. So the question arises, where is the teacup, really? Certainly there is a representation of the teacup inside your local computer, but there is also a representation of the teacup inside the server. And if I am in the room with you (well, my avatar, but that’s not important right now), then there’s also a representation of the teacup inside my local computer. So is the teacup in your computer or in my computer or in the server? One reasonable answer is “all of the above”, but in my experience a lot of technical people will say that it’s “really” in the server, since they regard the server as the source of truth. But the correct answer is that the teacup is on a table in a room inside a building in Populopolis. The teacup occupies a different plane of existence from the software objects that are used to realize it. It has an objective identity of its own — if you and I each refer to it, we are talking about the same teacup — but this identity is entirely distinct from the identities of any of those software objects. And it has such an identity, because even though it’s on a different plane there still needs to be some kind of actual identifier that can be used in the communications protocols that the clients and the server use to talk to each other, so that they can refer to the teacup when they describe their manipulations of it and the things that happen to it.
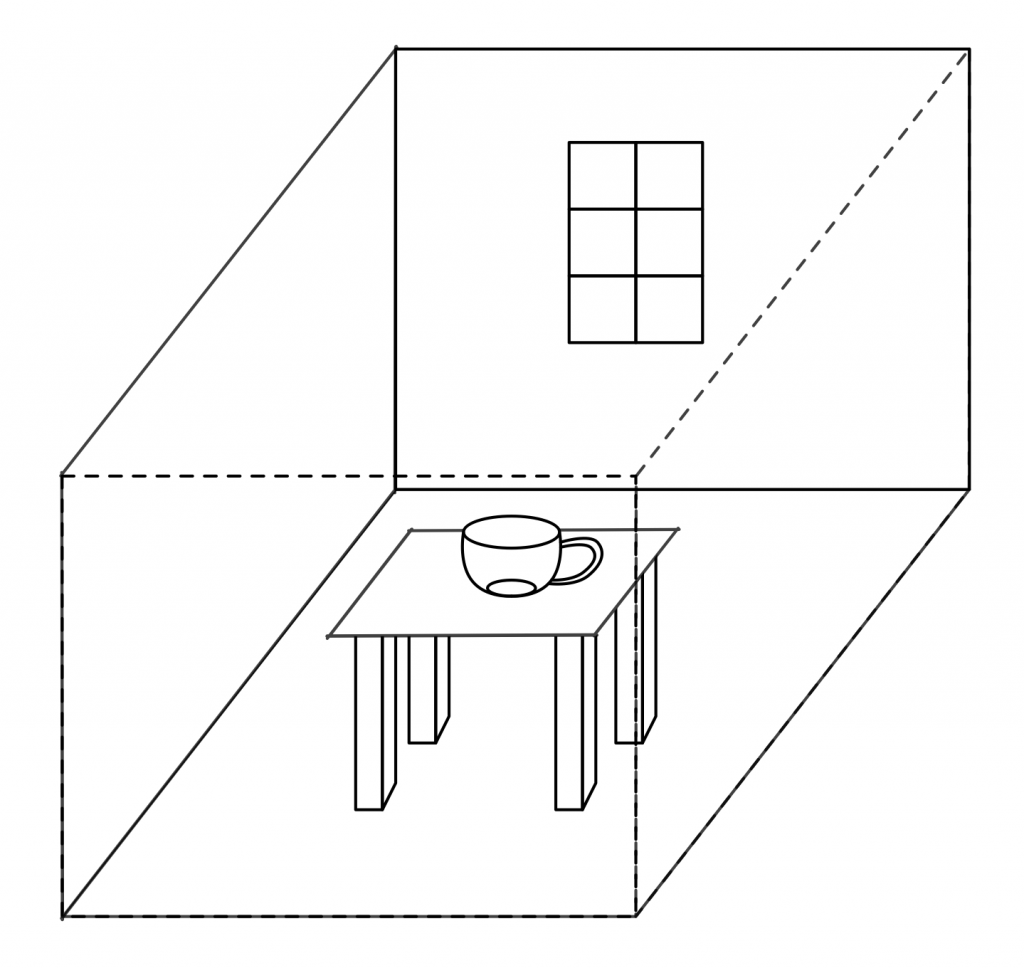
You might distinguish between these two senses of “object” by using phrases with modifiers; for example, you might say “world object” versus “OOP object”, and in fact that is what we did for several years. However, this terminology made it easy to fall back on the shorthand of just talking about “objects” when it was clear from context which of these two meanings of “object” you meant. Of course, it often turned out that this context wasn’t actually clear to somebody in the conversation, with confusion and misunderstanding as the common result. So after a few false starts at crafting alternative jargon we settled on using the term “object” to always refer to an OOP object in an implementation and the term “unum”, from the latin meaning a single thing, to refer to a world object. This term has worked well for us, aside from endless debates about whether the plural is properly “una” or “unums” (my opinion is: take your pick; people will know what you mean either way).
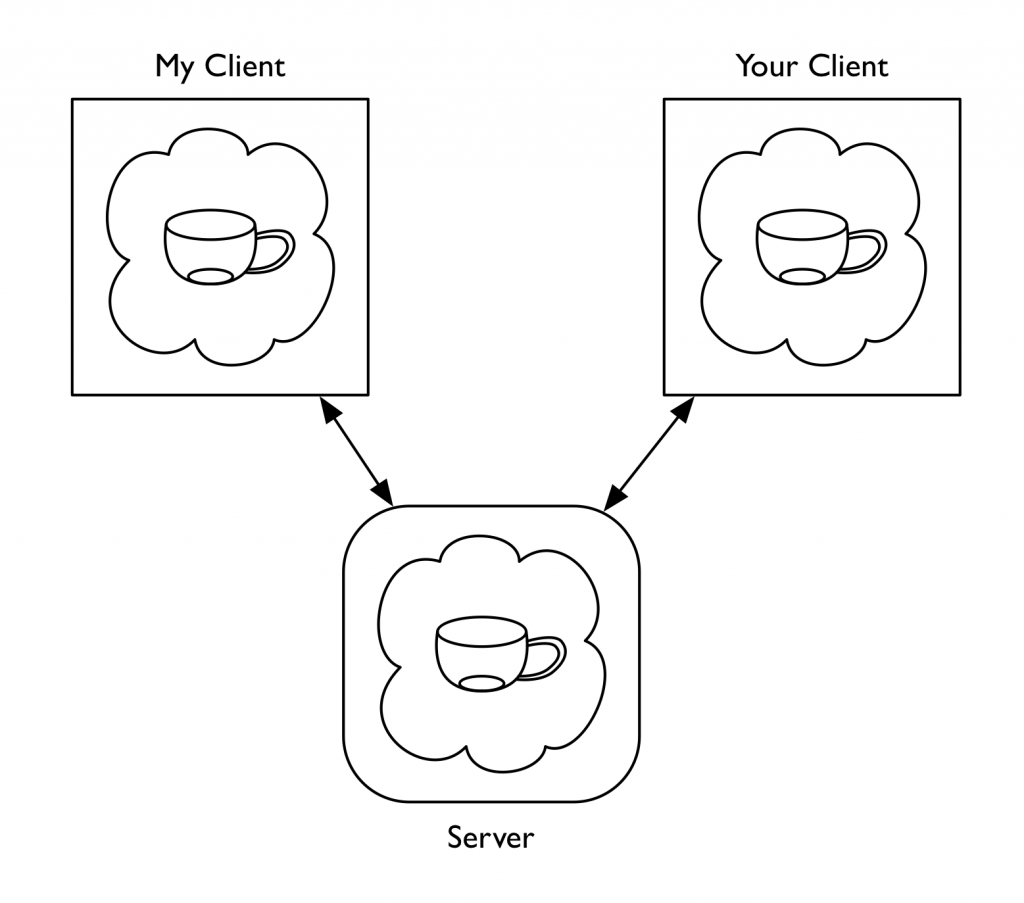
Of course, we still have to explain the relationship between the unum and its implementation. The objects (using that word from now on according to our revised terminology) that realize the unum do live at particular memory addresses in particular computers. We think of the unum, in contrast, as having a distributed existence. We speak of the portion of the unum that resides in a particular machine as a “presence”. So to go back to the example I started with, the teacup unum has a presence on the server and presences on each of our client machines.
(As an aside, for the first few years of trying to explain to people how Habitat worked, I would sometimes find myself in confused discussions about “distributed objects”, by which the people with whom I was talking meant individual objects that were located at different places on the network, whereas I meant objects that were themselves distributed entities. I didn’t at first realize these conversations were at cross purposes because the model we had developed for Habitat seemed natural and obvious to me at the time — how else could it possibly work, after all? — and it took me a while to twig to the fact that other people conceived of things in a very different way. Another reason for introducing a new word.)
In the teacup example, we have a server presence and some number of client presences. The client presences are concerned with presenting the unum to their local users while the server presence is concerned with keeping track of that portion of the unum’s state which all the users share. Phrased this way, many people find the presence abstraction very natural, but it sometimes leads them to jump to conclusions about what is going on, resulting in still more confusion and conversation at cross purposes. People who implement distributed systems often build on top of frameworks that provide services like data replication, and so it is easy to fall into thinking of the server presence as the “real” version of the unum and the client presences as shadow copies that maintain a (perhaps slightly out of date) cached representation of the true state. Or thinking of the client presences as proxies of some kind. This is not exactly wrong, in the sense that you can certainly build systems that work this way, as many distributed applications — possibly including most commercially successful MMOs — actually do. However, it’s not the model I’m describing here.
One problem with data replication based schemes is that they don’t gracefully accommodate use cases that require some information be withheld from some participants (it’s not that you absolutely can’t do this, but it’s awkward and cuts against the grain). It’s not just that the server is authoritative about shared state, but also that the server is allowed to take into account private state that the clients don’t have, in order to determine how the shared state changes over time and in response to events.
A server presence and a client presence are not doing the same job. The fundamental underlying concept that presences embody is not some notion of master vs. replica, but division of labor. Each has distinct responsibilities in the joint work of being the unum. Each is authoritative about different aspects of the unum’s existence (and typically each will maintain private state of their own that they do not share with the other). In the case of the client-server model in our example, the client presence manages client-side concerns such as the state of the display. It worries about things like 3D rendering, animation sequencing, and presenting controls to the human user to manipulate the teacup with. The server keeps track of things like the physical model of the teacup within the virtual world. It worries about the interactions between the teacup and the table, for example. Each presence knows things that are none of the other presence’s business, either because that information is simply outside the scope of what the other presence does (such as the current animation frame or the force being applied to the table) or because it’s something the other presence is not supposed to know (such as the server knowing that this particular teacup has a hidden flaw that will cause it to break into several pieces if you pour hot water into it, revealing a secret message inscribed on the edges where it comes apart). The various different client presences may also have information they do not share with each other for reasons of function or privacy. For example, one client might do 3D rendering in a GUI window while another presents only a textual description with a command line interface. Perhaps the server has revealed the secret message hidden in the teacup to my client (and to none of the others) because I possess a magic amulet that lets me see such things.
We can loosely talk about “sending a message to an unum”, but the sending of messages is an OOP concept rather than a world model concept. Sending a message to an unum (which is not an object) is really sending a message to some presence of that unum (since a presence is an object). This means that to designate the target of such a message, the address needs two components: (1) the identity of the unum and (2) an indicator of which presences of that unum you want to talk to.
In the systems I’ve implemented (including Habitat, but also, perhaps more usefully for anyone who wants to play with these ideas, its Nth generation descendant, the Elko server framework), the objects on a machine within a given application all run inside a common execution environment — what we now call a “vat”. Cross-machine messages are transported over communications channels established between vats. In such a system, from a vat’s perspective the external presences of a given unum (that is, presences other than the local one) are thus in one-to-one correspondence with the message channels to the other vats that host those presences, so you can designate a presence by indicating the channel that leads to its vat. (For those presences you can talk to, anyway: the unum model does not require that a presence be able to directly communicate with all the other presences. For example, in the case of a Habitat or Elko-style system such as I am describing here, clients don’t talk to other clients, but only to the server.)
Here we encounter an asymmetry between client and server that is another frequent source of confusion. From the client’s perspective, there is only one open message channel — the one that talks to the server — and so the only other unum presence a client knows about is the server presence. In this situation, the identifier of the unum is sufficient to determine where a message should be sent, since there is only one possibility. Developers working on client-side code don’t have to distinguish between “send a message to the unum” and “send a message to the server presence of the unum”. Consequently, they can program to the conventional model of “send messages to objects on the other end of the connection” and everything works more or less the way they are used to. On the server side, however, things get more interesting. Here we encounter something that people accustomed to developing in the web world have usually never experienced: server code that is simultaneously in communication with multiple clients. This is where working with the unum pattern suddenly becomes very different, and also where it acquires much of its power and usefulness.
In the client-server unum model, the server can communicate with all of an unum’s client presences. Although a given message could be sent to any of them, or to all of them, or to any arbitrary subset of them, in practice we’ve found that a small number of messaging patterns suffice to capture everything we’ve wanted to do. More specifically, there are four patterns that in our experience are repeatedly useful, to the point where we’ve codified these in the messaging libraries we use to implement distributed applications. We call these four messaging patterns Reply, Neighbor, Broadcast, and Point, all framed in the context of processing some message that has been received by the server presence from one of the clients; among other things, this context identifies which client it was who sent it. A Reply message is directed back to the client presence that sent the message the server is processing. A Point message is directed to a specific client presence chosen by the server; this is similar to a Reply message except that the recipient is explicit rather than implied and could be any client regardless of context. A Broadcast message is sent to all the client presences, while a Neighbor message is directed to all the client presences except the sender of the message that the server is processing. The latter pattern is the one that people coming to the unum model for the first time tend to find weird; I’ll explain its use in a moment.
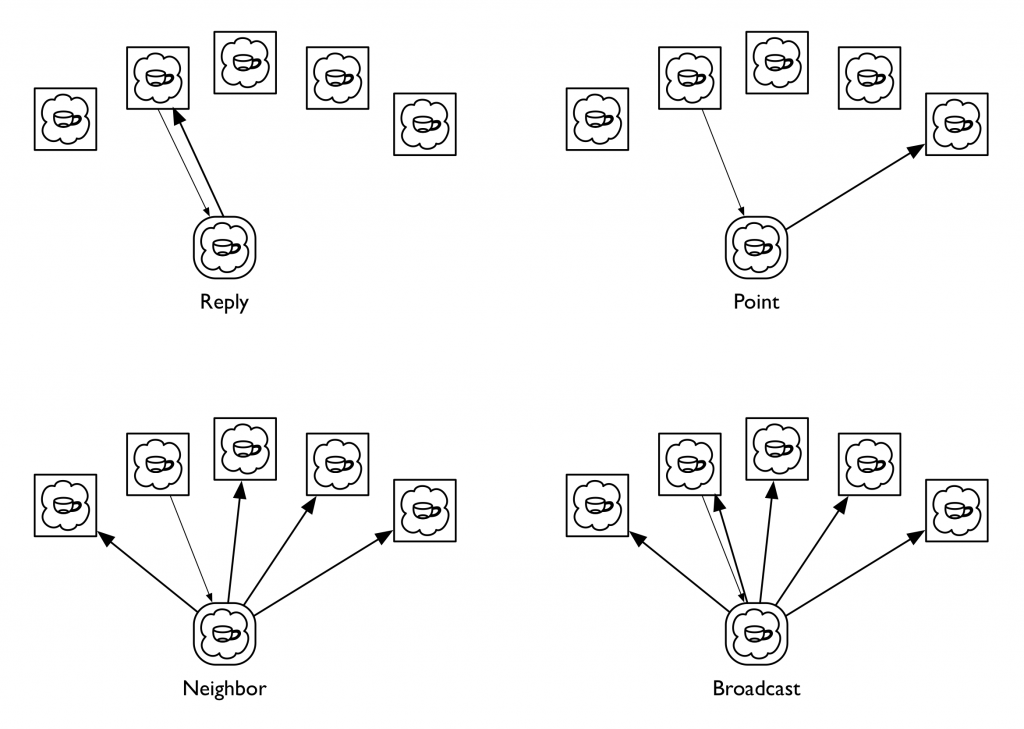
(Some people jump to the idea these four are all generalizations of the Point message, thinking it a good primitive to actually implement the other three, but in the systems we’ve built the messaging primitive is a lower level construct that handles fanout and routing for one or many recipients with a single, common mechanism so that we don’t have to multiply buffer the message if it has more than one target. In practice, we use Point messages rather rarely; in fact, using a Point message usually indicates that you’re doing something odd.)
The reason for there being multiple client presences in the first place is that the presences all share a common context in which the actions of one client can affect the others. This is in contrast to the classic web model in which each client is engaged in its own one-on-one dialog with the server, pretty much unrelated to any simultaneous dialogs the server might be having with other clients that just happen to be connected to it at the same time. However, the multiple-clients-in-a-shared-context model is a very good match for the kinds of online game and virtual world applications for which it was originated (it’s not that you can’t realize those kinds of applications using the web model, but, like the comment I made above about data replication, it’s cutting against the grain — it’s not a natural thing for web servers to do).
Actions initiated by a client typically take the form of a request message from that client to an unum’s server presence. The server’s handler for this message takes whatever actions are appropriate, then sends a Reply message back informing the requestor of the results of the action, along with a Neighbor message to the other client presences informing them of what just happened. The Reply and Neighbor messages generally have different payloads since the requestor typically already knows what’s going on and often merely needs a status result, whereas the other clients need to be informed of the action de novo. It is also common for the requestor to be a client that is in some privileged role with respect to the unum (perhaps the sending client is associated with the unum’s owner or holder, for example), and thus entitled to be given additional information in the Reply that is not shared with the other clients.
Actions initiated by the server, on the other hand, typically will be communicated to all the clients using the Broadcast pattern, since in this case none of the clients start out knowing what’s going on and thus all require the same information. The fact that the server can autonomously initiate actions is another difference between these kinds of systems and traditional web applications (server initiated actions are now supported by HTTP/2, albeit in a strange, inside out kind of way, but as far as I can tell they have yet to become part of the typical web application developer’s toolkit).
A direction that some people immediately want to go is to attempt to reduce the variety of messaging patterns by treating the coordination among presences as a data replication problem, which I’ve already said is not what we’re doing here. At the heart of this idea is a sense that you might make the development of presences simpler by reducing the differences between them — that rather than developing a client presence and a server presence as separate pieces of code, you could have a single implementation that will serve both ends of the connection (I can’t count the number of times I’ve seen game companies try to turn single player games into multiplayer games this way, and the results are usually pretty awful). Alternatively, one could implement one end and have the other be some kind of standardized one-side-fits-all thing that has no type-specific logic of its own. One issue with either of these approaches is how you handle the asymmetric information patterns inherent in the world model, but another is the division of labor itself. Systems built on the unum pattern tend to have message interfaces that are fundamentally about behavior rather than about data. That is, what is important about an unum is what it does. Habitat’s design was driven to a very large degree by the need for it to work effectively over 300 and 1200 baud connections. Behavioral protocols are vastly more effective at economizing on bandwidth than data based protocols. One way to think of this is as a form of highly optimized, knowledge-based data compression: if you already know what the possible actions are that can transform the state of something, a parameterized operation can often be represented much more compactly than can all state that is changed as a consequence of the action’s execution. In some sense, the unum pattern is about as anti-REST as you can be.
One idea that I think merits a lot more exploration is this: given the fundamental idea that an unum’s presences are factored according to a division of labor, are there other divisions of labor besides client-server that might be useful? I have a strong intuition that the answer is yes, but I don’t as yet have a lot of justification for that intuition. One obvious pattern to look into is a pure peer-to-peer model, where all presences are equally authoritative and the “true” state of reality is determined by some kind of distributed consensus mechanism. This is a notion we tinkered with a little bit at Electric Communities, but not to any particular conclusion. For the moment, this remains a research question.
One of the things we did do at Electric Communities was build a system where the client-server distinction was on a per-unum basis, rather than “client” and “server” being roles assigned to the two ends of a network connection. To return to our example of a teacup on a table in a room, you might have the server presence of the teacup be on machine A, with machines B and C acting as clients, while machine B is the server for the table and machine C is the server for the room. Obviously, this can only happen if there is N-way connectivity among all the participants, in contrast to the traditional two-way connectivity we use in the web, though whether this is realized via pairwise connections to a central routing hub or as a true crossbar is left as an implementation detail. This kind of per-unum relationship typing was one of the keys to our strategy for making our framework support a world that was both decentralized and openly extensible. (Continuing with the question raised in the last paragraph, an obvious generalization would be to allow the division of labor scheme itself vary from one unum to another. This suggests that a system whose unums are all initially structured according to the client-server model could still potentially act as a test bed for different schemes for dividing up functionality over the network.)
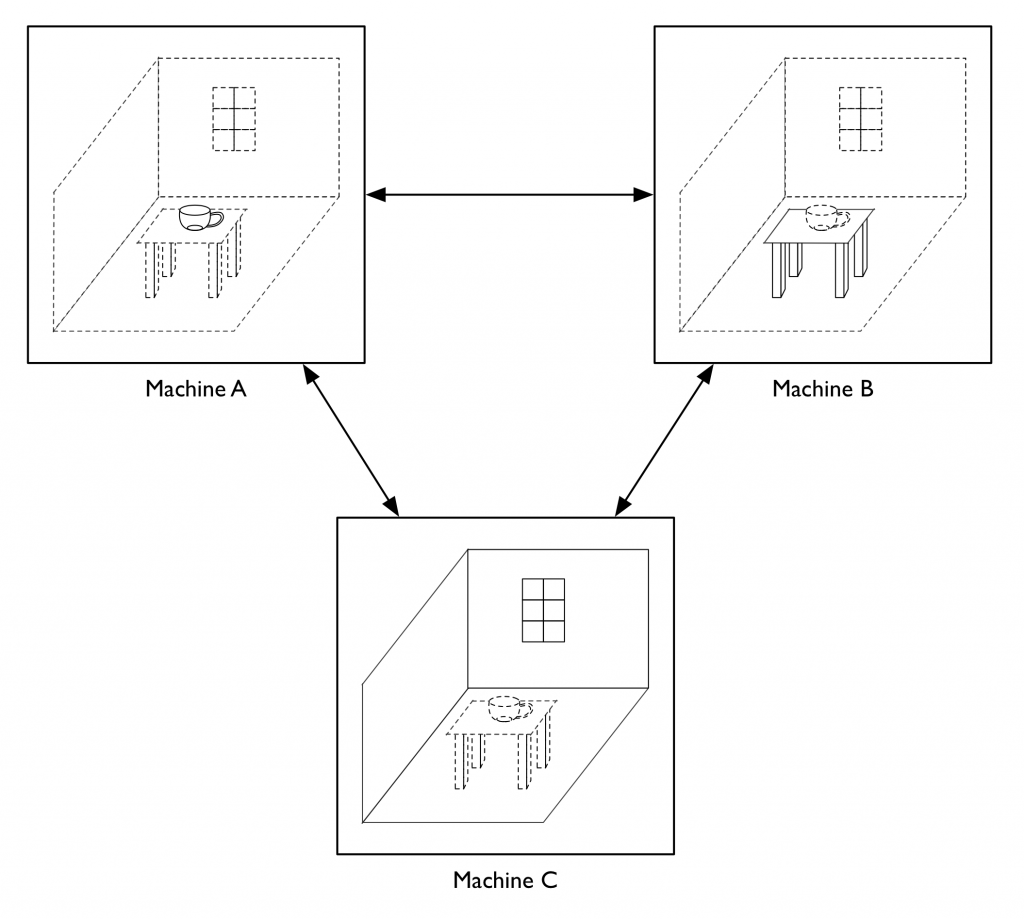
Having the locus of authoritativeness with respect to shared state vary from one unum to another opens up lots of interesting questions about the semantics of inter-unum relationships. In particular, there is a fairly broad set of issues that at Electric Communities we came to refer to as “the containership problem”, concerning how to model one unum containing another when the una are hosted on separate machines, and especially how to deal with changes in the containership relation. For example, let’s say we want to take our teacup that’s sitting on the table and put it into a box that’s on the table next to it. Is that an operation on the teacup or on the box? If we have the teacup be authoritative about what its container is, it could conceivably teleport itself from one place to another, or insert itself into places it doesn’t belong. On the other hand, if we have the box be authoritative about what it contains, then it could claim to contain (or not contain) anything it decides it wants. Obviously there needs to be some kind of handshake between the two (or between the three, if what we’re doing is moving an unum from one container to another, since both containers may have an interest — or among the two or three and whatever entity is initiating the change of containership, since that entity too may have something to say about things), but what form that handshake takes leads to a research program probably worthy of being somebody’s PhD thesis project.
Setting aside some of these more exotic possibilities for a moment, we have found the unum pattern to be a powerful and effective tool for implementing virtual worlds and lots of other applications that have some kind of world-like flavor, which, once you start looking at things through a world builder’s lens, is a fairly diverse lot, including smart contracts, multi-party negotiations, auctions, chat systems, presentation and conferencing systems, and, of course, all kinds of multiplayer games. And if you dig into some of the weirder things that we never had the chance to get into in too much depth, I think you have a rich universe of possibilities that is still ripe for exploration.
May 7, 2017
What Are Capabilities?
Some preliminary remarks
You can skip this initial section, which just sets some context, without loss to the technical substance of the essay that follows, though perhaps at some loss in entertainment value.
At a gathering of some of my coconspirators friends a couple months ago, Alan Karp lamented the lack of a good, basic introduction to capabilities for folks who aren’t already familiar with the paradigm. There’s been a lot written on the topic, but it seems like everything is either really long (though if you’re up for a great nerdy read I recommend Mark Miller’s PhD thesis), or really old (I think the root of the family tree is probably Dennis and Van Horn’s seminal paper from 1966), or embedded in explanations of specific programming languages (such as Marc Stiegler’s excellent E In A Walnut or the capabilities section of the Pony language tutorial) or operating systems (such as KeyKOS or seL4), or descriptions of things that use capabilities (like smart contracts or distributed file storage), or discussions of aspects of capabilities (Norm Hardy has written of ton of useful fragments on his website). But nothing that’s just a good “here, read this” that you can toss at curious people who are technically able but unfamiliar with the ideas. So Alan says, “somebody should write something like that,” while giving me a meaningful stare. Somebody, huh? OK, I can take a hint. I’ll give it a shot. Given my tendency to Explain Things this will probably end up being a lot longer than what Alan wants, but ya gotta start somewhere.
The first thing to confront is that term, “capabilities”, itself. It’s confusing. The word has a perfectly useful everyday meaning, even in the context of software engineering. When I was at PayPal, for example, people would regularly talk about our system’s capabilities, meaning what it can do. And this everyday meaning is actually pretty close to the technical meaning, because in both cases we’re talking about what a system “can” do, but usually what people mean by that is the functionality it realizes rather than the permissions it has been given. One path out of this terminological confusion takes its cue from the natural alignment between capabilities and object oriented programming, since it’s very easy to express capability concepts with object oriented abstractions (I’ll get into this shortly). This has lead, without too much loss of meaning, to the term “object capabilities”, which embraces this affinity. This phrase has the virtue that we can talk about it in abbreviated form as “ocaps” and slough off some of the lexical confusion even further. It does have the downside that there are some historically important capability systems that aren’t really what you’d think of as object oriented, but sometimes oversimplification is the price of clarity. The main thing is, just don’t let the word “capabilities” lead you down the garden path; instead, focus on the underlying ideas.
The other thing to be aware of is that there’s some controversy surrounding capabilities. Part of this is a natural immune response to criticism (nobody likes being told that they’re doing things all wrong), part of it is academic tribalism at work, and part of it is the engineer’s instinctive and often healthy wariness of novelty. I almost hesitate to mention this (some of my colleagues might argue I shouldn’t have), but it’s important to understand the historical context if you read through the literature. Some of the pushback these ideas have received doesn’t really have as much to do with their actual merits or lack thereof as one might hope; some of it is profoundly incorrect nonsense and should be called out as such.
The idea
Norm Hardy summarizes the capability mindset with the admonition “don’t separate designation from authority”. I like this a lot, but it’s the kind of zen aphorism that’s mainly useful to people who already understand it. To everybody else, it just invites questions: (a) What does that mean? and (b) Why should I care? So let’s take this apart and see…
The capability paradigm is about access control. When a system, such as an OS or a website, is presented with a request for a service it provides, it needs to decide if it should actually do what the requestor is asking for. The way it decides is what we’re talking about when we talk about access control. If you’re like most people, the first thing you’re likely to think of is to ask the requestor “who are you?” The fundamental insight of the capabilities paradigm is to recognize that this question is the first step on the road to perdition. That’s highly counterintuitive to most people, hence the related controversy.
For example, let’s say you’re editing a document in Microsoft Word, and you click on the “Save” button. This causes Word to issue a request to the operating system to write to the document file. The OS checks if you have write permission for that file and then allows or forbids the operation accordingly. Everybody thinks this is normal and natural. And in this case, it is: you asked Word, a program you chose to run, to write your changes to a file you own. The write succeeded because the operating system’s access control mechanism allowed it on account of it being your file, but that mechanism wasn’t doing quite what you might think. In particular, it didn’t check whether the specific file write operation in question was the one you asked for (because it can’t actually tell), it just checked if you were allowed to do it.
The access control model here is what’s known as an ACL, which stands for Access Control List. The basic idea is that for each thing the operating system wants to control access to (like a file, for example), it keeps a list of who is allowed to do what. The ACL model is how every current mainstream operating system handles this, so it doesn’t matter if we’re talking about Windows, macOS, Linux, FreeBSD, iOS, Android, or whatever. While there are a lot of variations in the details of how they they handle access control (e.g., the Unix file owner/group/others model, or the principal-per-app model common on phone OSs), in this respect they’re all fundamentally the same.
As I said, this all seems natural and intuitive to most people. It’s also fatally flawed. When you run an application, as far as the OS is concerned, everything the application does is done by you. Another way to put this is, an application you run can do anything you can do. This seems OK in the example we gave of Word saving your file. But what if Word did something else, like transmit the contents of your file over the internet to a server in Macedonia run by the mafia, or erase any of your files whose names begin with a vowel, or encrypt all your files and demand payment in bitcoins to decrypt them? Well, you’re allowed to do all those things, if for some crazy reason you wanted to, so it can too. Now, you might say, we trust Word not to do evil stuff like that. Microsoft would get in trouble. People would talk. And that’s true. But it’s not just Microsoft Word, it’s every single piece of software in your computer, including lots of stuff you don’t even know is there, much of it originating from sources far more difficult to hold accountable than Microsoft Corporation, if you even know who they are at all.
The underlying problem is that the access control mechanism has no way to determine what you really wanted. One way to deal with this might be to have the operating system ask you for confirmation each time a program wants to do something that is access controlled: “Is it OK for Word to write to this file, yes or no?” Experience with this approach has been pretty dismal. Completely aside from the fact that this is profoundly annoying, people quickly become trained to reflexively answer “yes” without a moment’s thought, since that’s almost always the right answer anyway and they just want to get on with whatever they’re doing. Plus, a lot of the access controlled operations a typical program does are internal things (like fiddling with a configuration file, for example) whose appropriateness the user has no way to determine anyhow.
An alternative approach starts by considering how you told Word what you wanted in the first place. When you first opened the document for editing, you typically either double-clicked on an icon representing the file, or picked the file from an Open File dialog. Note, by the way, that both of these user interface interactions are typically implemented by the operating system (or by libraries provided by the operating system), not by Word. The way current APIs work, what happens in either of these cases is that the operating system provides the application with a character string: the pathname of the file you chose. The application is then free to use this string however it likes, typically passing it as a parameter to another operating system API call to open the file. But this is actually a little weird: you designated a file, but the operating system turned this into a character string which it gave to Word, and then when Word actually wanted to open the file it passed the string back to the operating system, which converted it back into a file again. As I’ve said, this works fine in the normal case. But Word is not actually limited to using just the string that names the particular file you specified. It can pass any string it chooses to the Open File call, and the only access limitation it has is what permissions you have. If it’s your own computer, that’s likely to be permissions to everything on the machine, but certainly it’s at least permissions to all your stuff.
Now imagine things working a little differently. Imagine that when Word starts running it has no access at all to anything that’s access controlled – no files, peripheral devices, networks, nothing. When you double click the file icon or pick from the open file dialog, instead of giving Word a pathname string, the operating system itself opens the file and gives Word a handle to it (that is, it gives Word basically the same thing it would have given Word in response to the Open File API call when doing things the old way). Now Word has access to your document, but that’s all. It can’t send your file to Macedonia, because it doesn’t have access to the network – you didn’t give it that, you just gave it the document. It can’t delete or encrypt any of your other files, because it wasn’t given access to any of them either. It can mess up the one file you told it to edit, but it’s just the one file, and if it did that you’d stop using Word and not suffer any further damage. And notice that the user experience – your experience – is exactly the same as it was before. You didn’t have to answer any “mother may I?” security questions or put up with any of the other annoying stuff that people normally associate with security. In this world, that handle to the open file is an example of what we call a “capability”.
This is where we get back to Norm Hardy’s “don’t separate designation from authority” motto. By “designation” we mean how we indicate to, for example, the OS, which thing we are talking about. By “authority” we mean what we are allowed by the OS to do with that thing. In the traditional ACL world, these are two largely disconnected concepts. In the case of a file, the designator is typically a pathname – a character string – that you use to refer to the file when operating upon it. The OS provides operations like Write File or Delete File that are parameterized by the path name of the file to be written to or deleted. Authority is managed separately as an ACL that the OS maintains in association with each file. This means that the decision to grant access to a file is unrelated to the decision to make use of it. But this in turn means that the decision to grant access has to be made without knowledge of the specific uses. It means that the two pieces of information the operating system needs in order to make its access control decision travel to it via separate routes, with no assurance that they will be properly associated with each other when they arrive. In particular, it means that a program can often do things (or be fooled into doing things) that were never intended to be allowed.
Here’s the original example of the kind of thing I’m talking about, a tale from Norm. It’s important to note, by the way, that this is an actual true story, not something I just made up for pedagogical purposes.
Once upon a time, Norm worked for a company that ran a bunch of timeshared computers, kind of like what we now call “cloud computing” only with an earlier generation’s buzzwords. One service they provided was a FORTRAN compiler, so customers could write their own software.
It being so many generations of Moore’s Law ago, computing was expensive, so each time the compiler ran it wrote a billing record to a system accounting file noting the resources used, so the customer could be charged for them. Since this was a shared system, the operators knew to be careful with file permissions. So, for example, if you told the compiler to output to a file that belonged to somebody else, this would fail because you didn’t have permission. They also took care to make sure that only the compiler itself could write to the system accounting file – you wouldn’t want random users to mess with the billing records, that would obviously be bad.
Then one day somebody figured out they could tell the compiler the name of the system accounting file as the name of the file to write the compilation output to. The access control system looked at this and asked, “does this program have permission to write to this file?” – and it did! And so the compiler was allowed to overwrite the billing records and the billing information was lost and everybody got all their compilations for free that day.
Fixing this turned out to be surprisingly slippery. Norm named the underlying problem “The Confused Deputy”. At heart, the FORTRAN compiler was deputized by two different masters: the customer and the system operators. To serve the customer, it had been given permission to access the customer’s files. To serve the operators, it had been given permission to access the accounting file. But it was confused about which master it was serving for which purpose, because it had no way to associate the permissions it had with their intended uses. It couldn’t specify “use this permission for this file, use that permission for that file”, because the permissions themselves were not distinct things it could wield selectively – the compiler never actually saw or handled them directly. We call this sort of thing “ambient authority”, because it’s just sitting there in the environment, waiting to be used automatically without regard to intent or context.
If this system had been built on capability principles, rather than accessing the files by name, the compiler would instead have been given a capability by the system operators to access the accounting file with, which it would use to update the billing records, and then gotten a different capability from the customer to access the output file, which it would use when outputting the result of the compilation. There would have been no confusion and no exploit.
You might think this is some obscure problem those old people had back somewhere at the dawn of the industry, but a whole bunch of security problems plaguing us today – which you might think are all very different – fit this template, including many kinds of injection attacks, cross-site request forgery, cross site scripting attacks, click-jacking – including, depending on how you look at it, somewhere between 5 and 8 members of the OWASP top 10 list. These are all arguably confused deputy problems, manifestations of this one conceptual flaw first noticed in the 1970s!
Getting more precise
We said separating designation from authority is dangerous, and that instead these two things should be combined, but we didn’t really say much about what it actually means to combine them. So at this point I think it’s time to get a bit more precise about what a capability actually is.
A capability is single thing that both designates a resource and authorizes some kind of access to it.
There’s a bunch of abstract words in there, so let’s unpack it a bit.
By resource we just mean something the access control mechanism controls access to. It’s some specific thing we have that somebody might want to use somehow, whose use we seek to regulate. It could be a file, an I/O device, a network connection, a database record, or really any kind of object. The access control mechanism itself doesn’t much care what kind of thing the resource is or what someone wants to do with it. In specific use cases, of course, we care very much about those things, but then we’re talking about what we use the access control mechanism for, not about how it works.
In the same vein, when we talk about access, we just mean actually doing something that can be done with the resource. Access could be reading, writing, invoking, using, destroying, activating, or whatever. Once again, which of these it is is important for specific uses but not for the mechanism itself. Also, keep in mind that the specific kind of access that’s authorized is one of the things the capability embodies. Thus, for example, a read capability to a file is a different thing from a write capability to the same file (and of course, there might be a read+write capability to that file, which would be yet a third thing).
By designation, we mean indicating, somehow, specifically which resource we’re talking about. And by authorizing we mean that we are allowing the access to happen. Hopefully, none of this is any surprise.
Because the capability combines designation with authority, the possessor of the capability exercises their authority – that is, does whatever it is they are allowed to do with the resource the capability is a capability to – by wielding the capability itself. (What that means in practice should be clearer after a few examples). If you don’t possess the capability, you can’t use it, and thus you don’t have access. Access is regulated by controlling possession.
A key idea is that capabilities are transferrable, that someone who possesses a capability can convey it to someone else. An important implication that falls out of this is that capabilities fundamentally enable delegation of authority. If you are able to do something, it means you possess a capability for that something. If you pass this capability to somebody else, then they are now also able do whatever it is. Delegation is one of the main things that make capabilities powerful and useful. However, it also tends to cause a lot of people to freak out at the apparent loss of control. A common response is to try to invent mechanisms to limit or forbid delegation, which is a terrible idea and won’t work anyway, for reasons I’ll get into.
If you’re one of these people, please don’t freak out yourself; I’ll come back to this shortly and explain some important capability patterns that hopefully will address your concerns. In the meantime, a detail that might be helpful to meditate on: two capabilities that authorize the same access to the same resource are not necessarily the same capability (note: this is just a hint to tease the folks who are trying to guess where this goes, so if you’re not one of those people, don’t worry if it’s not obvious).
Another implication of our definition is that capabilities must be unforgeable. By this we mean that you can’t by yourself create a capability to a resource that you don’t already have access to. This is a basic requirement that any capability system must satisfy. For example, using pathnames to designate files is problematic because anybody can create any character string they want, which means they can designate any file they want if pathnames are how you do it. Pathnames are highly forgeable. They work fine as designators, but can’t by themselves be used to authorize access. In the same vein, an object pointer in C++ is forgeable, since you can typecast an integer into a pointer and thus produce a pointer to any kind of object at any memory address of your choosing, whereas in Java, Smalltalk, or pretty much any other memory-safe language where this kind of casting is not available, an object reference is unforgeable.
As I’ve talked about all this, I’ve tended to personify the entities that possess, transfer, and wield capabilities – for example, sometimes by referring to one of them as “you”. This has let me avoid saying much about what kind of entities these are. I did this so you wouldn’t get too anchored in specifics, because there are many different ways capability systems can work, and the kinds of actors that populate these systems vary. In particular, personification let me gloss over whether these actors were bits of software or actual people. However, we’re ultimately interested in building software, so now lets talk about these entities as “objects”, in the traditional way we speak of objects in object oriented programming. By getting under the hood a bit, I hope things may be made a little easier to understand. Later on we can generalize to other kinds of systems beyond OOP.
I’ll alert you now that I’ll still tend to personify these things a bit. It’s helpful for us humans, in trying to understand the actions of an intentional agent, to think of it as if it’s a person even if it’s really code. Plus – and I’ll admit to some conceptual ju-jitsu here – we really do want to talk about objects as distinct intentional agents. Another of the weaknesses of the ACL approach is that it roots everything in the identity of the user (or other vaguely user-like abstractions like roles, groups, service accounts, and so on) as if that user was the one doing things, that is, as if the user is the intentional agent. However, when an object actually does something it does it in a particular way that depends on how it is coded. While this behavior might reflect the intentions of the specific user who ultimately set it in motion, it might as easily reflect the intentions of the programmers who wrote it – more often, in fact, because most of what a typical piece of software does involves internal mechanics that we often work very hard to shield the user from having to know anything about.
In what we’re calling an “object capability” system (or “ocap” system, to use the convenient contraction I mentioned in the beginning), a reference to an object is a capability. The interesting thing about objects in such a system is that they are both wielders of capabilities and resources themselves. An object wields a capability – an object reference – by invoking methods on it. You transfer a capability by passing an object reference as a parameter in a method invocation, returning it from a method, or by storing it in a variable. An ocap system goes beyond an ordinary OOP system by imposing a couple additional requirements: (1) that object references be unforgeable, as just discussed, and (2) that there be some means of strong encapsulation, so that one object can hold onto references to other objects in a way that these can’t be accessed from outside it. For example, you can implement ocap principles in Java using ordinary Java object references held in private instance variables (to make Java itself into a pure ocap language – which you can totally do, by the way – requires introducing a few additional rules, but that’s more detail than we have time for here).
In an ocap system, there are only three possible ways you can come to have a capability to some resource, which is to say, to have a reference to some object: creation, transfer, and endowment.
Creation means you created the resource yourself. We follow the convention that, as a byproduct of the act of creation, the creator receives a capability that provides full access to the new resource. This is natural in an OOP system, where an object constructor typically returns a reference to the new object it constructed. In a sense, creation is an optional feature, because it’s not actually a requirement that a capability system have a way to produce new resources at all (that is, it might be limited to resources that already exist), but if it does, there needs to be way for the new resources to enter into the capability world, and handing them to their creator is a good way to do it.
Transfer means somebody else gave the capability to you. This is the most important and interesting case. Capability passing is how the authority graph – the map of who has what authority to do what with what – can change over time (by the way, the lack of a principled way to talk about how authorities change over time is another big problem with the ACL model). The simple idea is: Alice has a capability to Bob, Alice passes this capability to Carol, now Carol also has a capability to Bob. That simple narrative, however, conceals some important subtleties. First, Alice can only do this if she actually possesses the capability to Bob in the first place. Hopefully this isn’t surprising, but it is important. Second, Alice also has to have a capability to Carol (or some capability to communicate with Carol, which amounts to the same thing). Now things get interesting; it means we have a form of confinement, in that you can’t leak a capability unless you have another capability that lets you communicate with someone to whom you’d leak it. Third, Alice had to choose to pass the capability on; neither Bob nor Carol (nor anyone else) could cause the transfer without Alice’s participation (this is what motivates the requirement for strong encapsulation).
Endowment means you were born with the capability. An object’s creator can give it a reference to some other object as part of its initial state. In one sense, this is just creation followed by transfer. However, we treat endowment as its own thing for a couple of reasons. First, it’s how we can have an immutable object that holds a capability. Second, it’s how we avoid infinite regress when we follow the rules to their logical conclusion.
Endowment is how objects end up with capabilities that are realized by the ocap system implementation itself rather by code executing within it. What this means varies depending on the nature of the system; for example, an ocap language framework running on a conventional OS might provide a capability-oriented interface to the OS’s non-capability-oriented file system. An ocap operating system (such as KeyKOS or seL4) might provide capability-oriented access to primitive hardware resources such as disk blocks or network interfaces. In both cases we’re talking about things that exist outside the ocap model, which must be wrapped in special privileged objects that have native access to those things. Such objects can’t be created within the ocap rules, so they have to be endowed by the system itself.
So, to summarize: in the ocap model, a resource is an object and a capability is an object reference. The access that a given capability enables is the method interface that the object reference exposes. Another way to think of this is: ocaps are just object oriented programming with some additional strictness.
Here we come to another key difference from the ACL model: in the ocap world, the kinds of resources that may be access controlled, and the varieties of access to them that can be provided, are typically more diverse and more finely grained. They’re also generally more dynamic, since it’s usually possible, and indeed normal, to introduce new kinds of resources over time, with new kinds of access affordances, simply by defining new object classes. In contrast, the typical ACL framework has a fixed set of resource types baked into it, along with a small set of access modes that can be separately controlled. This difference is not fundamental – you could certainly create an extensible ACL system or an ocap framework based on a small, static set of object types – but it points to an important philosophical divergence between the two approaches.
In the ACL model, access decisions are made on the basis of access configuration settings associated with the resources. These settings must be administered, often manually, by direct interaction with the access control machinery, typically using tools that are part of the access control system itself. While policy abstractions (such as groups or roles, for example) can reduce the need for humans to make large numbers of individual configuration decisions, it is typically the case that each resource acquires its access control settings as the consequence of people making deliberate access configuration choices for it.
In contrast, the ocap approach dispenses with most of this configuration information and its attendant administrative activity. The vast majority of access control decisions are realized by the logic of how the resources themselves operate. Most access control choices are subsumed by the code of the corresponding objects. At the granularity of individual objects, the decisions to be made are usually simple and clear from context, further reducing the cognitive burden. Only at the periphery, where the system comes into actual contact with its human users, do questions of policy and human intent arise. And in many of these cases, intent can be inferred from the normal acts of control and designation that users make through their normal UI interactions (such as picking a file from a dialog or clicking on a save button, to return to the example we began with).
Consequently, thinking about access control policy and administration is an entirely different activity in an ocap system than in an ACL system. This thinking extends into the fundamental architecture of applications themselves, as well as that of things like programming languages, application frameworks, network protocols, and operating systems.
Capability patterns
To give you a taste of what I mean by affecting fundamental architecture, let’s fulfill the promise I made earlier to talk about how we address some of the concerns that someone from a more traditional ACL background might have.
The ocap approach both enables and relies on compositionality – putting things together in different ways to make new kinds of things. This isn’t really part of the ACL toolbox at all. The word “compositionality” is kind of vague, so I’ll illustrate what I’m talking about with some specific capability patterns. For discussion purposes, I’m going to group these patterns into a few rough categories: modulation, attenuation, abstraction, and combination. Note that there’s nothing fundamental about these, they’re just useful for presentation.
Modulation
By modulation, I mean having one object modulate access to another. The most important example of this is called a revoker. A major source of the anxiety that some people from an ACL background have about capabilities is the feeling that a capability can easily escape their control. If I’ve given someone access to some resource, what happens if later I decide it’s inappropriate for them to have it? In the ACL model, the answer appears to be simple: I merely remove that person’s entry from the resource’s ACL. In the ocap model, if I’ve given them one of my capabilities, then now they have it too, so what can I do if I don’t want them to have it any more? The answer is that I didn’t give them my capability. Instead I gave them a new capability that I created, a reference to an intermediate object that holds my capability but remains controlled by me in a way that lets me disable it later. We call such a thing a revoker, because it can revoke access. A rudimentary form of this is just a simple message forwarder that can be commanded to drop its forwarding pointer.
Modulation can be more sophisticated than simple revocation. For example, I could provide someone with a capability that I can switch on or off at will. I could make access conditional on time or date or location. I could put controls on the frequency or quantity of use (a use-once capability with a built-in expiration date might be particularly useful). I could even make an intermediary object that requires payment in exchange for access. The possibilities are limited only by need and imagination.
The revoker pattern solves the problem of taking away access, but what about controlling delegation? Capabilities are essentially bearer instruments – they convey their authority to whoever holds them, without regard to who the holder is. This means that if I give someone a capability, they could pass it to someone else whose access I don’t approve of. This is another big source of anxiety for people in the ACL camp: the idea that in the capability model there’s no way to know who has access. This is not rooted in some misunderstanding of capabilities either; it’s actually true. But the ACL model doesn’t really help with this, because it has the same problem.
In real world use cases, the need to share resources and to delegate access is very common. Since the ACL model provides no mechanism for this, people fall back on sharing credentials, often in the face of corporate policies or terms of use that specifically forbid this. When presented with the choice between following the rules and getting their job done, people will often pick the latter. Consider, for example, how common it is for a secretary or executive assistant to know their boss’s password – in my experience, it’s almost universal.
There’s a widespread belief that an ACL tells you who has access, but this is just an illusion, due to the fact that credential sharing is invisible to the access control system. What you really have is something that tells you who to hold responsible if a resource is used inappropriately. And if you think about it, this is what you actually want anyway. The ocap model also supports this type of accountability, but can do a much better job of it.
The first problem with credential sharing is that it’s far too permissive. If my boss gives me their company LDAP password so I can access their calendar and email, they’re also giving me access to everything else that’s protected by that password, which might extend to things like sensitive financial or personnel records, or even the power to spend money from the company bank account. Capabilities, in contrast, allow them to selectively grant me access to specific things.
The second problem with credential sharing is that if I use my access inappropriately, there’s no way to distinguish my accesses from theirs. It’s hard for my boss to claim “my flunky did it!” if the activity logs are tied to the boss’s name, especially if they weren’t supposed to have shared the credentials in the first place. And of course this risk applies in the other direction as well: if it’s an open secret that I have my boss’s password, suspicion for their misbehavior can fall on me; indeed, if my boss was malicious they might share credentials just to gain plausible deniability when they abscond with company assets. The revoker pattern, however, can be extended to enable delegation to be auditable. I delegate by passing someone an intermediary object that takes note of who is being delegated to and why, and then it can record this information in an audit log when it is used. Now, if the resource is misused, we actually know who to blame.
Keep in mind also that credential sharing isn’t limited to shared passwords. For example, if somebody asks me to run a program for them, then whatever it is that they wanted done by that program gets done using my credentials. Even if what the program did was benign and the request was made with the best of intentions, we’ve still lost track of who was responsible. This is the reason why some companies forbid running software they haven’t approved on company computers.
Attenuation
When I talk about attenuation, I mean reducing what a capability lets you do – its scope of authority. The scope of authority can encompass both the operations that are enabled and the range of resources that can be accessed. The later is particularly important, because it’s quite common for methods on an object’s API to return references to other objects as a result (once again, a concept that is foreign to the ACL world). For example, one might have a capability that gives access to a computer’s file system. Using this, an attenuator object might instead provide access only to a specific file, or perhaps to some discrete sub-directory tree in a file hierarchy (i.e., a less clumsy version of what the Unix chroot operation does).
Attenuating functionality is also possible. For example, the base capability to a file might allow any operation the underlying file system supports: read, write, append, delete, truncate, etc. From this you can readily produce a read-only capability to the same file: simply have the intermediary object support read requests without providing any other file API methods.
Of course, these are composable: one could readily produce a read-only capability to a particular file from a capability providing unlimited access to an entire file system. Attenuators are particularly useful for packaging access to the existing, non-capability oriented world into capabilities. In addition to the hierarchical file system wrapper just described, attenuators are helpful for mediating access to network communications (for example, limiting connections to particular domains, allowing applications to be securely distributed across datacenters without also enabling them talk to arbitrary hosts on the internet – the sort of thing that would normally be regulated by firewall configuration, but without the operational overhead or administrative inconvenience). Another use would be controlling access to specific portions of the rendering surface of a display device, something that many window systems already do in an almost capability-like fashion anyway.
Abstraction
Abstraction enters the picture because once we have narrowed what authority a given capability represents, it often makes sense to refactor what it does into something with a more appropriately narrow set of affordances. For example, it might make sense to package the read-only file capability mentioned above into an input stream object, rather than something that represents a file per se. At this point you might ask if this is really any different from ordinary good object oriented programming practice. The short answer is, it’s not – capabilities and OOP are strongly aligned, as I’ve mentioned several times already. A somewhat longer answer is that the capability perspective usefully shapes how you design interfaces.
A core idea that capability enthusiasts use heavily is the Principle of Least Authority (abbreviated POLA, happily pronounceable). The principle states that objects should be given only the specific authority necessary to do their jobs, and no more. The idea is that the fewer things an object can do, the less harm can result if it misbehaves or if its integrity is breached.
Least Authority is related to the notions of Least Privilege or Least Permission that you’ll frequently see in a lot of the traditional (non-capability) security literature. In part, this difference in jargon is just a cultural marker that separates the two camps. Often the traditional literature will tell you that authority and permission and privilege all mean more or less the same thing.
However, we really do prefer to talk about “authority”, which we take to represent the full scope of what someone or something is able to do, whereas “permission” refers to a particular set of access settings. For example, on a Unix system I typically don’t have permission to modify the /etc/passwd file, but I do typically have permission to execute the passwd command, which does have permission to modify the file. This command will make selected changes to the file on my behalf, thus giving me the authority to change my password. We also think of authority in terms of what you can actually do. To continue the example of the passwd command, it has permission to delete the password file entirely, but it does not make this available to me, thus it does not convey that authority to me even though it could if it were programmed to do so.
The passwd command is an example of abstracting away the low level details of file access and data formats, instead repackaging them into a more specific set of operations that is more directly meaningful to its user. This kind of functionality refactoring is very natural from a programming perspective, but using it to also refactor access is awkward in the ACL case. ACL systems typically have to leverage slippery abstractions like the Unix setuid mechanism. Setuid is what makes the Unix passwd command possible in the first place, but it’s a potent source of confused deputy problems that’s difficult to use safely; an astonishing number of Unix security exploits over the years have involved setuid missteps. The ocap approach avoids these missteps because the appropriate reduction in authority often comes for free as a natural consequence of the straightforward implementation of the operation being provided.
Combination
When I talk about combination, I mean using two or more capabilities together to create a new capability to some specific joint functionality. In some cases, this is simply the intersection of two different authorities. However, the more interesting cases are when we put things together to create something truly new.
For example, imagine a smartphone running a capability oriented operating system instead of iOS or Android. The hardware features of such a phone would, of course, be accessed via capabilities, which the OS would hand out to applications according to configuration rules or user input. So we could imagine combining three important capabilities: the authority to capture images using the camera, the authority to obtain the device’s geographic position via its built-in GPS receiver, and the authority to read the system clock. These could be encapsulated inside an object, along with a (possibly manufacturer provided) private cryptographic key, yielding a new capability that when invoked provides signed, authenticated, time stamped, geo-referenced images from the camera. This capability could then be granted to applications that require high integrity imaging, like police body cameras, automobile dash cams, journalistic apps, and so on. If this capability is the only way for such applications to get access to the camera at all, then the applications’ developers don’t have to be trusted to maintain a secure chain of evidence for the imagery. This both simplifies their implementation task – they can focus their efforts on their applications’ unique needs instead of fiddling with signatures and image formats – and makes their output far more trustworthy, since they don’t have prove their application code doesn’t tamper with the data (you still have to trust the phone and the OS, but that’s at least a separable problem).
What can we do with this?
I’ve talked at length about the virtues of the capability approach, but at the same time observed repeatedly (if only in criticism) that this is not how most contemporary systems work. So even if these ideas are as virtuous as I maintain they are, we’re still left with the question of what use we can make of them absent some counterfactual universe of technical wonderfulness.
There are several ways these ideas can provide direct value without first demanding that we replace the entire installed base of software that makes the world go. This is not to say that the installed base never gets replaced, but it’s a gradual, incremental process. It’s driven by small, local changes rather than by the unfolding of some kind of authoritative master plan. So here are a few incremental ways to apply these ideas to the current world. My hope is that these can deliver enough immediate value to bias practitioners in a positive direction, shaping the incentive landscape so it tilts towards a less dysfunctional software ecosystem. Four areas in particular seem salient to me in this regard: embedded systems, compartmentalized computation, distributed services, and software engineering practices.
Embedded systems
Capability principles are a very good way to organize an operating system. Two of the most noteworthy examples, in my opinion, are KeyKOS and seL4.
KeyKOS was developed in the 1980s for IBM mainframes by Key Logic, a spinoff from Tymshare. In addition to being a fully capability secure OS, it attained extraordinarily high reliability via an amazing, high performance orthogonal persistence mechanism that allowed processes to run indefinitely, surviving things like loss of power or hardware failure. Some commercial KeyKOS installations had processes that ran for years, in a few cases even spanning replacement of the underlying computer on which they were running. Towards the end of its commercial life, KeyKOS was also ported to several other processor architectures, making it a potentially interesting jumping off point for further development. KeyKOS has inspired a number of follow ons, including Eros, CapROS, and Coyotos. Unfortunately most of these efforts have been significantly resource starved and consequently have not yet had much real world impact. But the code for KeyKOS and its descendants is out there for the taking if anybody wants to give it a go.
seL4 is a secure variant of the L4 operating system, developed by NICTA in Australia. While building on the earlier L3 and L4 microkernels, seL4 is a from scratch design heavily influenced by KeyKOS. seL4 notably has a formal proof of functional correctness, making it an extremely sound basis for building secure and reliable systems. It’s starting to make promising inroads into applications that demand this kind of assurance, such as military avionics. Like KeyKOS, seL4, as well as seL4’s associated suite of proofs, is available as open source software.
Embedded systems, including much of the so called “Internet of Things”, are sometimes less constrained by installed base issues on account of being standalone products with narrow functionality, rather than general purpose computational systems. They often have fewer points where legacy interoperability is as important. Moreover, they’re usually cross-developed with tools that already expect the development and runtime environments to be completely different, allowing them to be bootstrapped via legacy toolchains. In other words, you don’t have to port your entire development system to the new OS in order to take advantage of it, but rather can continue using most of your existing tools and workflow processes. This is certainly true of the capability OS efforts I just mentioned, which have all dealt with these issues.
Furthermore, embedded software is often found in mission critical systems that must function reliably in a high threat environment. In these applications, reliability and security can take priority over cost minimization, making the assurances that a capability OS can offer comparatively more attractive. Consequently, using one of these operating systems as the basis for a new embedded application platform seems like an opportunity, particularly in areas where reliability is important.
A number of recent security incidents on the internet have revolved around compromised IoT devices. A big part of the problem is that the application code in these products typically has complete access to everything in the device, largely as a convenience to the developers. This massive violation of least privilege then makes these devices highly vulnerable to exploitation when an attacker finds flaws in the application code.
Rigorously compartmentalizing available functionality would greatly reduce the chances of these kinds of vulnerabilities, but this usually doesn’t happen. Partly this is just ignorance – most of these developers are not generally also security experts, especially when the things they are working on are not, on their face, security sensitive applications. However, I think a bigger issue is that the effort and inconvenience involved in building a secure system with current building blocks doesn’t seem justified by the payoff.
No doubt the developers of these products would prefer to produce more secure systems than they often do, all other things being equal, but all other things are rarely equal. One way to tilt the balance in our favor would be to give them a platform that more or less automatically delivers desirable security and reliability properties as a consequence of developers simply following the path of least resistance. This is the payoff that building on top of a capability OS offers.
Compartmentalized computation
Norm Hardy – one of the primary architects of KeyKOS, who I’ve already mentioned several times – has quipped that “the last piece of software anyone ever writes for a secure, capability OS is always the Unix virtualization layer.” This is a depressing testimony to the power that the installed base has over the software ecosystem. However, it also suggests an important benefit that these kinds of OS’s can provide, even in an era when Linux is the defacto standard.
In the new world of cloud computing, virtualization is increasingly how everything gets done. Safety-through-compartmentalization has long been one of the key selling points driving this trend. The idea is that even if an individual VM is compromised due to an exploitable flaw in the particular mix of application code, libraries, and OS services that it happens to be running, this does not gain the attacker access to other, adjacent VMs running on the same hardware.
The underlying idea – isolate independent pieces of computation so they can’t interfere with each other – is not new. It is to computer science what vision is to evolutionary biology, an immensely useful trick that gets reinvented over and over again in different contexts. In particular, it’s a key idea motivating the architecture of most multitasking operating systems in the first place. Process isolation has long been the standard way for keeping one application from messing up another. What virtualization brings to the table is to give application and service operators control over a raft of version and configuration management issues that were traditionally out of their hands, typically in the domain of the operators of the underlying systems on which they were running. Thus, for example, even if everyone in your company is using Linux it could still be the case that a service you manage depends on some Apache module that only works on Linux version X, while another some other wing of your company has a service requiring a version of MySQL that only works with Linux version Y. But with virtualization you don’t need to fight about which version of Linux to run on your company server machines. Instead, you can each have your own VMs running whichever version you need. More significantly, even if the virtualization system itself requires Linux version Z, it’s still not a problem, because it’s at a different layer of abstraction.
Virtualization doesn’t just free us from fights over which version of Linux to use, but which operating system entirely. With virtualization you can run Linux on Windows, or Windows on Mac, or FreeBSD on Linux, or whatever. In particular, it means you can run Linux on seL4. This is interesting because all the mainstream operating systems have structural vulnerabilities that mean they inevitably tend to get breached, and when somebody gets into the OS that’s running the virtualization layer it means they get into all the hosted VMs as well, regardless of their OS. While it’s still early days, initial indications are that seL4 makes a much more solid base for the virtualization layer than Linux or the others, while still allowing the vast bulk of the code that needs to run to continue working in its familiar environment.
By providing a secure base for the virtualization layer, you can provide a safe place to stand for datacenter operators and other providers of virtualized services. You have to replace some of the software that manages your datacenter, but the datacenter’s customers don’t have to change anything to benefit from this; indeed, they need not even be aware that you’ve done it.
This idea of giving applications a secure place to run, a place where the rules make sense and critical invariants can be relied upon – what I like to call an island of sanity – is not limited to hardware virtualization. “Frozen Realms”, currently working its slow way through the JavaScript standardization process, is a proposal to apply ocap-based compartmentalization principles to the execution environment of JavaScript code in the web browser.
The stock JavaScript environment is highly plastic; code can rearrange, reconfigure, redefine, and extend what’s there to an extraordinary degree. This massive flexibility is both blessing and curse. On the blessing side, it’s just plain useful. In particular, a piece of code that relies on features or behavior from a newer version of the language standard can patch the environment of an older implementation to emulate the newer pieces that it needs (albeit sometimes with a substantial performance penalty). This malleability is essential to how the language evolves without breaking the web. On the other hand, it makes it treacherous to combine code from different providers, since it’s very easy for one chunk of code to undermine the invariants that another part relies on. This is a substantial maintenance burden for application developers, and especially for the creators of application frameworks and widely used libraries. And this before we even consider what can happen if code behaves maliciously.
Frozen Realms is a scheme to let you to create an isolated execution environment, configure it with whatever modifications and enhancements it requires, lock it down so that it is henceforth immutable, and then load and execute code within it. One of the goals of Frozen Realms is to enable defensively consistent software – code that can protect its invariants against arbitrary or improper behavior by things it’s interoperating with. In a frozen realm, you can rely on things not to change beneath you unpredictably. In particular, you could load independent pieces of software from separate developers (who perhaps don’t entirely trust each other) into a common realm, and then allow these to interact safely. Ocaps are key to making this work. All of the ocap coding patterns mentioned earlier become available as trustworthy tools, since the requisite invariants are guaranteed. Because the environment is immutable, the only way pieces of code can affect each other is via object references they pass between them. Because all external authority enters the environment via object references originating outside it, rather than being ambiently available, you have control over what any piece of code will be allowed to do. Most significantly, you can have assurances about what it will not be allowed to do.
Distributed services
There are many problems in the distributed services arena for which the capability approach can be helpful. In the interest of not making this already long essay even longer, I’ll just talk here about one of the most important: the service chaining problem, for which the ACL approach has no satisfactory solution at all.
The web is a vast ecosystem of services using services using services. This is especially true in the corporate world, where companies routinely contract with specialized service providers to administer non-core operational functions like benefits, payroll, travel, and so on. These service providers often call upon even more specialized services from a range of other providers. Thus, for example, booking a business trip may involve going through your company’s corporate intranet to the website of the company’s contracted travel agency, which in turn invokes services provided by airlines, hotels, and car rental companies to book reservations or purchase tickets. Those services may themselves call out to yet other services to do things like email you your travel itinerary or arrange to send you a text if your flight is delayed.
Now we have the question: if you invoke one service that makes use of another, whose credentials should be used to access the second one? If the upstream service uses its own credentials, then it might be fooled, by intention or accident, into doing something on your behalf that it is allowed to do but which the downstream service wouldn’t let you do (a classic instance of the Confused Deputy problem). On the other hand, if the upstream service needs your credentials to invoke the downstream service, it can now do things that you wouldn’t allow. In fact, by giving it your credentials, you’ve empowered it to impersonate you however it likes. And the same issues arise for each service invocation farther down the chain.
Consider, for example, a service like Mint that keeps track of your finances and gives you money management advice. In order to do this, they need to access banks, brokerages, and credit card companies to obtain your financial data. When you sign up for Mint, you give them the login names and passwords for all your accounts at all the financial institutions you do business with, so they can fetch your information and organize it for you. While they promise they’re only going to use these credentials to read your data, you’re actually giving them unlimited access and trusting them not to abuse it. There’s no reason to believe they have any intention of breaking their promise, and they do, in fact, take security very seriously. But in the end the guarantee you get comes down to “we’re a big company, if we messed with you too badly we might get in trouble”; there are no technical assurances they can really provide. Instead, they display the logos of various security promoting consortia and double pinky swear they’ll guard your credentials with like really strong encryption and stuff. Moreover, their terms of use work really hard to persuade you that you have no recourse if they fail (though who actually gets stuck holding the bag in the event they have a major security breach is, I suspect, virgin territory, legally speaking).
While I’m quite critical of them here, I’m not actually writing this to beat up on them. I’m reasonably confident (and I say this without knowing or having spoken to anyone there, merely on the basis of having been in management at various companies myself) that they would strongly prefer not to be in the business of running a giant single point of failure for millions of people’s finances. It’s just that given the legacy security architecture of the web, they have no practical alternative, so they accept the risk as a cost of doing business, and then invest in a lot of complex, messy, and very expensive security infrastructure to try to minimize that risk.
To someone steeped in capability concepts, the idea that you would willingly give strangers on the web unlimited access to all your financial accounts seems like madness. I suspect it also seems like madness to lay people who haven’t drunk the conventional computer security kool aid, evidence of which is the lengths Mint has to go to in its marketing materials trying to persuade prospective customers that, no really, this is OK, trust us, please pay no attention to the elephant in the room.
The capability alternative (which, I stress, is not an option currently available to you), would be to obtain a separate credential – a capability! – from each of your financial institutions that you could pass along to a data management service like Mint. These credentials would grant read access to the relevant portions of your data, while providing no other authority. They would also be revocable, so that you could unilaterally withdraw this access later, say in the event of a security breach at the data manager, without disrupting your own normal access to your financial institutions. And there would be distinct credentials to give to each data manager that you use (say, you’re trying out a competitor to Mint) so that they could be independently controlled.
There are no particular technical obstacles to doing any of this. Alan Karp worked out much of the mechanics at HP Labs in a very informative paper called “Zebra Copy: A reference implementation of federated access management” that should be on everyone’s must read list.
Even with existing infrastructure and tools there are many available implementation options. Alan worked it out using SAML certificates, but you can do this just as well with OAuth2 bearer tokens, or even just special URLs. There are some new user interface things that would have to be done to make this easy and relatively transparent for users, but there’s been a fair bit of experimentation and prototyping done in this area that have pointed to a number of very satisfactory and practical UI options. The real problem is that the various providers and consumers of data and services would all have to agree that this new way of doing things is desirable, and then commit to switching over to it, and then standardize the protocols involved, and then actually change their systems, whereas the status quo doesn’t require any such coordination. In other words, we’re back to the installed base problem mentioned earlier.
However, web companies and other large enterprises are constantly developing and deploying hordes of new services that need to interoperate, so even if the capability approach is an overreach for the incumbents, it looks to me like a competitive opportunity for ambitious upstarts. Enterprises in particular currently lack a satisfactory service chaining solution, even though they’re in dire need of one.
In practice, the main defense against bad things happening in these sorts of systems is not the access control mechanisms at all, it’s the contractual obligations between the various parties. This can be adequate for big companies doing business with other big companies, but it’s not a sound basis for a robust service ecosystem. In particular, you’d like software developers to be able to build services by combining other services without the involvement of lawyers. And in any case, when something does go wrong, with or without lawyers it can be hard to determine who to hold at fault because confused deputy problems are rooted in losing track of who was trying to do what. In essence we have engineered everything with built in accountability laundering.
ACL proponents typically try to patch the inherent problems of identity-based access controls (that is, ones rooted in the “who are you?” question) by piling on more complicated mechanisms like role-based access control or attribute-based access control or policy-based access control (Google these if you want to know more; they’re not worth describing here). None of these schemes actually solves the problem, because they’re all at heart just variations of the same one broken thing: ambient authority. I think it’s time for somebody to try to get away from that.
Software engineering practices
At Electric Communities we set out to create technology for building a fully decentralized, fully user extensible virtual world. By “fully decentralized” we meant that different people and organizations could run different parts of the world on their own machines for specific purposes or with specific creative intentions of their own. By “fully user extensible” we meant that folks could add new objects to the world over time, and not just new objects but new kinds of objects.
Accomplishing this requires solving some rather hairy authority management problems. One example that we used as a touchstone was the notion of a fantasy role playing game environment adjacent to an online stock exchange. Obviously you don’t want someone taking their dwarf axe into the stock exchange and whacking peoples’ heads off, nor do you want a stock trader visiting the RPG during their lunch break to have their portfolio stolen by brigands. While interconnecting these two disparate applications doesn’t actually make a lot of sense, it does vividly capture the flavor of problems we were trying to solve. For example, if the dwarf axe is a user programmed object, how does it acquire the ability to whack people’s heads off in one place but not have that ability in another place?
Naturally, ocaps became our power tool of choice, and lots of interesting and innovative technology resulted (the E programming language is one notable example that actually made it to the outside world). However, all the necessary infrastructure was ridiculously ambitious, and consequently development was expensive and time consuming. Unfortunately, extensible virtual world technology was not actually something the market desperately craved, so being expensive and time consuming was a problem. As a result, the company was forced to pivot for survival, turning its attentions to other, related businesses and applications we hoped would be more viable.
I mention all of the above as preamble to what happened next. When we shifted to other lines of business, we did so with a portfolio of aggressive technologies and paranoid techniques forged in the crucible of this outrageous virtual world project. We went on using these tools mainly because they were familiar and readily at hand, rather than due to some profound motivating principle, though we did retain our embrace of the ocap mindset. However, when we did this, we made an unexpected discovery: code produced with these tools and techniques had greater odds of being correct on the first try compared to historical experience. A higher proportion of development time went to designing and coding, a smaller fraction of time to debugging, things came together much more quickly, and the resulting product tended to be considerably more robust and reliable. Hmmm, it seems we were onto something here. The key insight is that measures that prevent deliberate misbehavior tend to be good at preventing accidental misbehavior also. Since a bug is, almost by definition, a form of accidental misbehavior, the result was fewer bugs.
Shorn of all the exotic technology, however, the principles at work here are quite simple and very easy to apply to ordinary programming practice, though the consequences you experience may be far reaching.
As an example, I’ll explain how we apply these ideas to Java. There’s nothing magic or special about Java per se, other than it can be tamed – some languages cannot – and that we’ve had a lot of experience doing so. In Java we can reduce most of it to three simple rules:
- Rule #1: All instance variables must be private
- Rule #2: No mutable static state or statically accessible authority
- Rule #3: No mutable state accessible across thread boundaries
That’s basically it, though Rule #2 does merit a little further explication. Rule #2 means that all static variables must be declared final and may only reference objects that are themselves transitively immutable. Moreover, constructors and static methods must not provide access to any mutable state or side-effects on the outside world (such as I/O), unless these are obtained via objects passed into them as parameters.
These rules simply ensure the qualities of reference unforgeability and encapsulation that I mentioned a while back. The avoidance of static state and static authority is because Java class names constitute a form of forgeable reference, since anyone can access a class just by typing its name. For example, anybody at all can try to read a file by creating an instance of java.io.FileInputStream, since this will open a file given a string. The only limitations on opening a file this way are imposed by the operating system’s ACL mechanism, the very thing we are trying to avoid relying on. On the other hand, a specific instance of java.io.InputStream is essentially a read capability, since the only authority it exposes is on its instance methods.
These rules cover most of what you need. If you want to get really extreme about having a pure ocap language, in Java there are a few additional edge case things you’d like to be careful of. And, of course, it would also be nice if the rules could be enforced automatically by your development tools. If your thinking runs along these lines, I highly recommend checking out Adrian Mettler’s Joe-E, which defines a pure ocap subset of Java much more rigorously, and provides an Eclipse plugin that supports it. However, simply following these three rules in your ordinary coding will give you about 90% of the benefits if what you care about is improving your code rather than security per se.
Applying these rules in practice will change your code in profound ways. In particular, many of the standard Java class libraries don’t follow them – for example lots of I/O authority is accessed via constructors and static methods. In practice, what you do is quarantine all the unavoidable violations of Rule #2 into carefully considered factory classes that you use during your program’s startup phase. This can feel awkward at first, but it’s an experience rather like using a strongly typed programming language for the first time: in the beginning you keep wondering why you’re blocked from doing obvious things you want to do, and then it slowly dawns on you that actually you’ve been blocked from doing things that tend to get you into trouble. Plus, the discipline forces you to think through things like your I/O architecture, and the result is generally improved structure and greater robustness.
(Dealing with the standard Java class libraries is a bit of an open issue. The approach taken by Joe-E and its brethren has been to use the standard libraries pruned of the dangerous stuff, a process we call “taming”. But while this yields safety, it’s less than ideal from an ergonomics perspective. A project to produce a good set of capability-oriented wrappers for the functionality in the core Java library classes would probably be a valuable contribution to the community, if anyone out there is so inclined.)
Something like the three rules for Java can be often devised for other languages as well, though the feasibility of this does vary quite a bit depending on how disciplined the language in question is. For example, people have done this for Scala and OCaml, and it should be quite straightforward for C#, but probably hopeless for PHP or Fortran. Whether C++ is redeemable in this sense is an open question; it seems plausible to me, although the requisite discipline somewhat cuts against the grain of how people use C++. It’s definitely possible for JavaScript, as a number of features in recent versions of the language standard were put there expressly to enable this kind of thing. It’s probably also worth pointing out that there’s a vibrant community of open source developers creating new languages that apply these ideas. In particular, you should check out Monte, which takes Python as its jumping off point, and Pony, which is really its own thing but very promising.
There’s a fairly soft boundary here between practices that simply improve the robustness and reliability of your code if you follow them, and things that actively block various species of bad outcomes from happening. Obviously, the stronger the discipline enforced by the tools is, the stronger the assurances you’ll have about the resulting product. Once again, the analogy to data types comes to mind, where there are best practices that are basically just conventions to be followed, and then there are things enforced, to a greater or lesser degree, by the programming language itself. From my own perspective, the good news is that in the short term you can start applying these practices in the places where it’s practical to do so and get immediate benefit, without having to change everything else. In the long term, I expect language, library, and framework developers to deliver us increasingly strong tools that will enforce these kinds of rules natively.
Conclusion
At its heart, the capability paradigm is about organizing access control around specific acts of authorization rather than around identity. Identity is so fundamental to how we interact with each other as human beings, and how we have historically interacted with our institutions, that it is easy to automatically assume it should be central to organizing our interactions with our tools as well. But identity is not always the best place to start, because it often fails to tell us what we really need to know to make an access decision (plus, it often says far too much about other things, but that’s an entirely separate discussion).
Organizing access control around the question “who are you?” is incoherent, because the answer is fundamentally fuzzy. The driving intuition is that the human who clicked a button or typed a command is the person who wanted whatever it was to happen. But this is not obviously true, and in some important cases it’s not true at all. Consider, for example, interacting with a website using your browser. Who is the intentional agent in this scenario? Well, obviously there’s you. But also there are the authors of every piece of software that sits between you and the site. This includes your operating system, the web browser itself, the web server, its operating system, and any other major subsystems involved on your end or theirs, plus the thousands of commercial and open source libraries that have been incorporated into these systems. And possibly other stuff running on your (or their) computers at the time. Plus intermediaries like your household or corporate wireless access point, not to mention endless proxies, routers, switches, and whatnot in the communications path from here to there. And since you’re on a web page, there’s whatever scripting is on the page itself, which includes not only the main content provided by the site operators but any of the other third party stuff one typically finds on the web, such as ads, plus another unpredictably large bundle of libraries and frameworks that were used to cobble the whole site together. Is it really correct to say that any action taken by this vast pile of software was taken by you? Even though the software has literally tens of thousands of authors with a breathtakingly wide scope of interests and objectives? Do you really want to grant all those people the power to act as you? I’m fairly sure you don’t, but that’s pretty much what you’re actually doing, quite possibly thousands of times per day. The question that the capability crowd keeps asking is, “why?”
Several years ago, the computer security guru Marcus Ranum wrote: “After all, if the conventional wisdom was working, the rate of systems being compromised would be going down, wouldn’t it?” I have no idea where he stands on capabilities, nor if he’s even aware of them, but this assertion still seems on point to me.
I’m on record comparing the current state of computer security to the state of medicine at the dawn of the germ theory of disease. I’d like to think of capabilities as computer security’s germ theory. The analogy is imperfect, of course, since germ theory talks about causality whereas here we’re talking about the right sort of building blocks to use. But I keep being drawn back to the parallel largely because of the ugly and painful history of germ theory’s slow acceptance. On countless occasions I’ve presented capability ideas to folks who I think ought know about them – security people, engineers, bosses. The typical response is not argument, but indifference. The most common pushback, when it happens, is some variation of “you may well be right, but…”, usually followed by some expression of helplessness or passive acceptance of the status quo. I’ve had people enthusiastically agree with everything I’ve said, then go on to behave as if these ideas had never ever entered their brains. People have trouble absorbing ideas that they don’t already have at least some tentative place for in their mental model of the world; this is just how human minds work. My hope is that some of the stuff I’ve written here will have given these ideas a toehold in your head.
Acknowledgements
This essay benefitted from a lot of helpful feedback from various members of the Capabilities Mafia, the Friam group, and the cap-talk mailing list, notably David Bruant, Raoul Duke, Bill Frantz, Norm Hardy, Carl Hewitt, Chris Hibbert, Baldur Jóhannsson, Alan Karp, Kris Kowal, William Leslie, Mark Miller, David Nicol, Kevin Reid, and Dale Schumacher. My thanks to all of them, whose collective input improved things considerably, though of course any remaining errors and infelicities are mine.
August 26, 2013
Randy’s Got a Podcast: Social Media Clarity
![]()
I’ve teamed up with Bryce Glass and Marc Smith to create a podcast – here’s the link and the blurb:
Social Media Clarity – 15 minutes of concentrated analysis and advice about social media in platform and product design.
First episode contents:
News: Rumor – Facebook is about to limit 3rd party app access to user data!
Topic: What is a social network, why should a product designer care, and where do you get one?
Tip: NodeXL – Instant Social Network Analysis
July 7, 2010
RealID and WoW Forums: Classic Identity Design Mistake
Update #3, July 14th 4pm PST: GamePro interviewed Howard Rheingold and myself for a good analysis piece in which I add some new thoughts, including a likely-to-be-controversial comparison to a certain Arizona state law…
Update #2, July 9th 1pm PST: KillTenRats.com just posted an email interview on this topic that I did for them yesterday. There some potentially useful business analysis in there, and more specific suggestions, even if it now feels a bit like residual heat from a flamethrower fest…
Hey Blizzard! I’m a freelance consultant! Just sayin’ :-)
Update #1, July 9th 10am PST: Blizzard has had a change of heart and will not require RealID for forum postings. This is a big win both for the community, and I believe, for Blizzard! The post below remains only as a historical footnote and perhaps a cautionary tale…
Talk about a crapstorm…
Here’s my latest tweet:
@frandallfarmer Quit World of Warcraft. New policy of RealID for forums - stupid beyond belief. #wow #fail #realid #reputation #identity #quit #copa #coppa
That’s too terse, given the magnitude of the error that Blizzard is making, so here’s a longer post…
Identity as Defense?
Blizzard has announced that the upcoming Starcraft II forums will require posts to be attributed to the user’s read-life name, taken from their billing information. As if this wasn’t bad enough, they’ve also said that the World of Warcraft boards will start this requirement soon as well.
They also announced a posting rating system, which sounds like they haven’t read anything from Building Web Reputation Systems, or at least about the massive disasters from combining real names and social ratings at places like Consumating.com, but that’s a post for a different blog. :-)
The idea Blizzard has is a common initial misconception – that people will “play nice” if they have to show their real names to each other. I’m sure they are using Facebook as an example – I often do this in my consulting practice. There is no doubt that Facebook users are better behaved in general than their YouTube counterparts, but the error Blizzard made is to assume that their player relationships are like those of Facebook.
This is critical misconception, and the community is responding with the longest threads in WoW history, and blog posts everywhere.
The Misconceptions
There are a lot of valid (and invalid) complaints and fears about this change – I’m not going to list them all here. What I want to do is point out the fundamental flaws in this model, for WoW in particular.
My 35+ years in building online communities (with and without RealID-like systems) screams out that Blizzard is going to be very, very disappointed with the results of this change. Specifically:
1: Names != Quality
Though this is nominally meant to improve the quality of the community, by civilizing conversation through revealing true names, it won’t because the interesting conversation will simply stop or move elsewhere. Many women (including a Blizzard employee) have already clearly stated that they won’t post anymore. This kind of thing has happened many times before as communities move from Yahoo Groups to Ning or wherever. As John Gilmore said:
“The Net interprets censorship as damage and routes around it.”
2: Brain Drain or “NetNews died for our sins”
Some say that getting rid of (bad) people is what Blizzard wants, so point #1 is a plus. But hold on there! Just owning the problem of driving customers into silence or away doesn’t help either.
Consider the case of Usenet/Netnews, where all the great internet community was until 1994 – when the environment became inhospitable to types of discussions the natives wanted to have, and they left en masse to form private mailing lists, and eventually webblogs. The assertion that a community of those who will reveal their names is somehow better does NOT hold up to any reasonable scrutiny (see next point…)
A shocking number of people who leave will be amonst the best users Blizzard has – and that could kill the quality of content on the forums, just as happened with NetNews. Sure, less trollish posts, but less great posters too. I’m betting there are less trolls to remove than there are good users who’ll leave/not post.
3: Facebook Status != Message Board Participation
I approve my Facebook Friends. None of them are trolls/spammy – or if they are, I block their events and no harm done. All of them can see my real name, status postings, comments, and other personal information. If it turns out I’m sharing too much, I can turn down the disclosure. It’s all optional.
Message boards are public. Readable by God, Google and Everyone. This model requires me to disclose sensitive information to everyone. Completely different.
Here’s the deal. We’re talking gaming here. People will get pissed at each other for stolen kills, breaking alliances, and the price of components – and they want to – no, they need to – have a safe place to express this, to play.
This is my spare time. It’s no other player’s business where I work, where I live, who my family is. Just as it’s no business of my boss, who knows how to Google my name, what I dedicate my off-hours energy to. The Facebook-analogy of Real Identity = Quality Contributions falls apart when applied Gaming. Google + Friends + Foes + Bosses + My Real Name + The fact I have 6 80th Level Characters = Too Much Information.
Facebook does NOT leak this much information, and the US Senate is looking into their privacy practices.
This has also happened many times before. Every time someone new to the net starts a LiveJournal, they don’t know about friends locking until they get asked into the boss’s office to discuss something they read on the journal while ego-surfing. This is how many LiveJournals get owner-deleted!
It is completely unreasonable to expect that people will understand the risks of using their real names on a message board – and if they DO understand, I contend that most people won’t bother posting anything at all.
In short:
- The trolls now get more information to harass
- The best players will leave
- The casual players will panic when they realize that their private-time activity is now public.
This is lose-lose. The worst kind of change. The only upside I see is the ability to lay off board moderation staff as traffic (good and bad) plummets.
An Alternative Everyone Can Live With
There was/is an alternative – described in the Tripartite Identity Model post from two years ago: Implement Nicknames!
Sure, have a top-level social identity, but present it as user-controlled Nickname and allow users to share a variant of their real name – but don’t require it! Sure, if the Nickname is the same as their RealID, feel free to show an indicator, like Amazon.com does with their Real Nametm markers. Allow users to reveal what they wish – even provide incentives for them to do so, but don’t bind full disclosure on them. Even Facebook doesn’t do this!
It’s never too late.
P.S.: I can’t stop being amazed – Asking for help on a forum requires disclosing your real name to God, Google, and Everyone? Come on! You’ve got to be kidding!
February 24, 2010
Grizzled Advice from Business & Legal Primer for Game Development
[Two years ago, I wrote up a few lessons for inclusion in Business & Legal Primer for Game Development. I’d always meant to cross-post it here and was surprised to see I hadn’t already when I went looking for it to share with the folks over at PlayNoEvil in reply to a recent post. – Randy]
Here are three top-line lessons for those considering designing their own MMORG or latest Facebook game for that matter…
1. Design Hubris Wastes Millions
Read all the papers/books/blogs written by your predecessors that you can – multi-user game designers are pretty chatty about their successes and failures. Pay close attention to their failures – try not to duplicate those. Believe it or not, several documented failures have been repeated over and over in multiple games, despite these freely available resources.
If you are going to ignore one of the lessons of those who went before, presumably because you think you know a better way, do it with your eyes wide open and be ready to change to plan B if your innovation doesn’t work out the way you expected. If you want to hash your idea out before committing it to code, consider consulting with the more experienced designers – they post on Terra Nova (http://blogs.terranova.com/) and talk to budding designers on the Mud-Dev (http://www.kanga.nu/) mailing list, amongst other places. Many of them respond pretty positively to direct contact via email – just be polite and ask your question clearly – after all, they are busy building their own worlds.
2. Beta Testers != Paying Customers
One recurring error in multi-user game testing is the problem of assuming that Beta users of a product will behave like real customers would. They don’t, for several reasons:
A. Beta testing is a status symbol amongst their peers
“I’m in the ZYXWorld Limited Beta!” is a bragging right. Since it has street-cred value, this leads the user to be on their best behavior. They will grief much less. They will share EULA breaking hacks with each other much less. They will harass much less. They won’t report duping bugs. The eBay aftermarket for goods won’t exist. In short, anything that would get them kicked out of the beta won’t happen anywhere near as often as when the product is released.
B. Beta testers aren’t paying.
Paying changes everything. During the Beta, the users work for you. When you release the game, you are working for them. Now some users will expect to be allowed to do all sorts of nasty things that they would never had done during the Beta. Those who were Beta users (and behaved then) will start to exploit bugs they found during the test period, but never reported. Bad beta users save up bugs, so they could use them after your product’s release to gain an edge over the new users, to dupe gold, or to just crash your server to show off to a friend.
So, you’re probably wondering; How do I get my Beta testers to show me what life on my service will really be like and to help me find the important bugs/exploits/crashes before I ship? Here are some strategies that worked for projects I worked on:
Crash Our World: Own up to the fact that Beta testers work for you and they do it for the status – incentivize the finding of crash/dup/exploit bugs that you want them to find. Give them a t-shirt for finding one. Put their portrait on the Beta Hall Of Fame page. Give them a rare in-world item that they can carry on into general release. Drop a monument in the world, listing the names of the testers that submitted the most heinous bugs. Turn it into a contest. Make it more valuable to report a bug than to keep it secret.
Pay-ta: Run a Paid Beta phase (after Crash Our World) to find out how users will interact with each other socially (or using your in-game social/communications features.) During this phase of testing you will get better results about which social features to prioritize/fix for release. Encourage and/or track the creation of fan communities, content databases, and add-ons – it will help you understand what to prepare for, as well as build word-of-mouth marketing. But, keep in mind that there is one thing you can never really test in advance: How your user community will socially scale. As the number of users grows, the type of user will diversify. For most games, the hard-core gamers come first and the casual players come later. Be sure to have a community manager whose job it is to track customer sentiment and understand the main player groups. How your community scales will challenge your development priorities and the choices you make will have you trading off new-customer acquisition vs. veteran player retention.
3. There Are No Game Secrets, Period
Thanks to the internet – in-game puzzles are solved for everyone at the speed of the fastest solver. Read about “The D’nalsi Island” adventure in Lucasfilm’s Habitat where the players consumed hundreds of development hours in only tens of minutes.
The Lesson? Don’t count on secrets to hold up for long. Instead, treat game walk-thru websites as a feature to be embraced instead of the bane of your existence. “But,” you’ll say, “I could create a version of my puzzle that is customized (randomized) for every user! That will slow them down!” Don’t bother; it will only upset your users.
The Tragedy of the Tapers
Consider the example of the per-player customized spell system in the original Asheron’s Call (by Turbine, Inc.): Each magic spell was designed to consume various types of several resources: scarabs, herbs, powders, potions, and colored tapers. The designers thought it would be great to have the users actually learn the spells by having to discover them through experimentation. The formula was different for every spell and the tapers were different for every user.
One can just hear the designer saying “That’ll fix those Internet spoilers! With this system, they each have to learn their own spells!” But, instead of feeling enjoyment, the players became frustrated with what seemed to be nothing other than a waste of their time and resources burning spell components as they were compelled to try the complete set of exponential combinations of tapers for no good reason.
What was interesting is that the users got frustrated enough to actually figure out the exact method of generating the random seed to determine the tapers for each user as follows:
Second Taper = (SEED * [ Talisman + (Herb + 3) + ((Powder + Potion) * 2) + (Scarab – 2) ] ) mod 12
[Modified from Jon Krueger’s web page on the subject.]
The players put this all into a client plug-in to remove the calculation overhead, and were now able to correctly formulate the spells the very first time they tried. Unfortunately, this meant that new users (who didn’t know about the plug-in) were likely to have a significantly poorer experience than veterans.
To Turbine’s credit, they revised the game in its second year to remove the need for most of the spell components and created rainbow tapers, which worked for all users in all spells, completely canceling the original per-player design.
Hundreds of thousands of dollars went into that spell system. The users made a large chunk of that effort obsolete very quickly, and Turbine then had to pay for more development and testing to undo their design.
Learn from Turbine’s mistake; Focus on making your game fun even if the player can look up all the answers in a database or a plug-in.
Don’t start a secrecy arms-war with your user. You’ll lose. Remember: There are more of them than you and collectively they have more time to work on your product than you do.
December 5, 2009
The Cake is a Lie: Reputation, Facebook Apps, and “Consent” User Interfaces
This is a cross-post from Randy’s other blog Building Web Reputation Systems and all comments should be directed there.
In early November, I attended the 9th meeting of the Internet Identity Workshop. One of the working sessions I attended was on Social Consent user interface design. After the session, I had an insight that reputation might play a pivotal role in solving one of the key challenges presented. I shared my detailed, yet simple, idea with Kevin Marks and he encouraged me to share my thoughts through a blog post—so here goes…
The Problem: Consent Dialogs
The technical requirements for the dialog are pretty simple: applications have to ask users for permission to access their sensitive personal data in order to produce the desired output—whether that’s to create an invitation list, or to draw a pretty graph, or to create a personalized high-score table including your friends, or to simply sign and attach an optional profile photo to a blog comment.

The problem, however, is this—users often don’t understand what they are being asked to provide, or the risks posed by granting access. It’s not uncommon for a trivial quiz application to request access to virtually the same amount of data as much more “heavyweight”applications (like, say, an app to migrate your data between social networks.) Explaining this to users—in any reasonable level of detail—just before running the application causes them to (perhaps rightfully) get spooked and abandon the permission grant.
Conflicting Interests
The platform providers want to make sure that their users are making as informed a decision as possible, and that unscrupulous applications don’t take advantage of their users.
The application developers want to keep the barriers to entry as low as possible. This fact creates a lot of pressure to (over)simplify the consent flow. One designer quipped that it reduces the user decision to a dialog with only two buttons: “Go” and “Go Away” (and no other text.)
The working group made no real progress. Kevin proposed creating categories, but that didn’t get anywhere because it just moved the problem onto user education—”What permissions does QuizApp grant again?”
Reputation to the Rescue?
All consent dialogs of this stripe suffer from the same problem: Users are asked to make a trust decision about an application that, by definition, they know nothing about!
This is where identity meets trust, and that’s the kind of problem that reputation is perfect for. Applications should have reputations in the platform’s database. That reputation can be displayed as part of the information provided when granting consent.
Here’s one proposed model (others are possible, this is offered as an exemplar).
The Cake is a Lie: Your Friends as Canaries in the Coal Mine of New Apps
First a formalism: when an application wants to access a user’s private Information (I), they have a set of intended Purposes (P) they wish to use it for. Therefore, the consent could be phrased thusly:
“If you let me have your (I), I will give you (P). [Grant] [Deny]”
Example: “If you give me access to your friends list, I will give you cake.”
In this system, I propose that the applications be compelled to declare this formulation as part of the consent API call. (P) would be stored along with the app’s record in the platform database. So far, this is only slightly different from what we have now, and of course, the application could omit or distort the request.
This is where the reputation comes in. Whenever a user uninstalls an application, the user is asked to provide a reason, including abusive use of data and specifically asks a question to see if the promise of (P) was kept.
“Did this application give you the [cake] it promised?”
All negative feedback is kept—to be re-used later when other new users install the app and encounter the consent dialog. If they have friends who have uninstalled this application already complaining that “If (I) then (P)” string was false, then the moral equivalent of this would appear scrawled in the consent box:

“Randy says the [cake] was unsatisfactory.
Bryce says the [cake] was unsatisfactory.
Pamela says the application spammed her friends list.”
Afterthoughts
Lots of improvements are possible (not limiting it to friends, and letting early-adopters know that they are canaries in the coal mine.) These are left for future discussion.
Sure, this doesn’t help early adopters.
But application reputation quickly shuts down apps that do obviously evil stuff.
Most importantly, it provides some insight to users by which they can make more informed consent decisions.
(And if you don’t get the cake reference, you obviously haven’t been playing Portal.)
September 6, 2009
Elko II: Against Statelessness (or, Everything Old Is New Again)
Preface: This is second of three posts on Elko, a server platform for sessionful, stateful web applications that I’m releasing this week as open source software. Part I, posted yesterday, presented the business backstory for Elko. This post presents the technical backstory: it lays out the key ideas that lead to the thing. Part III which will be posted tomorrow, presents a more detailed technical explication of the system itself.
It seems to be an article of faith in the web hosting and web server development communities that one of the most expensive resources that gets used up on a web server is open TCP connections. Consequently, a modern web server goes to great lengths to try to close any open TCP connection it can as soon as possible. Symptoms of this syndrome include short timeouts on HTTP Keep-Alive sessions (typically on the order of 10 seconds) and connection pool size limits on reverse proxies, gateways, and the like (indeed, a number of strange limits of various kinds seem to appear nearly any time you see the word “pool” used in any server related jargon). These guys really, really, really want to close that connection.
In the world as I see it, the most expensive thing is not an open connection per se. The cost of an open but inactive TCP connection is trivial: state data structures measured in the tens or hundreds of bytes, and buffer space measured in perhaps tens of kilobytes. Keeping hundreds of thousands of simultaneous inactive connections open on a single server (i.e., vastly more connections than the server would be able to service if they were all active) is really not that big a deal.
The expense I care about is the client latency associated with opening a new TCP connection. Over IP networks, just about the most expensive operation there is is opening a new TCP connection. In my more cynical moments, I imagine web guys thinking that since it is expensive, it must be valuable, so if we strive to do it as frequently as possible, we must be giving the users a lot of value, hence HTTP. However, the notable thing about this cost is that it is borne by the user, who pays it by sitting there waiting, whereas the cost of ongoing open connections is paid by the server owner.
So why do we have this IHMO upside down set of valuation memes driving the infrastructure of the net?
The answer, in part, lies in the architecture of a lot of server software, most notably Apache. Apache is not only the leading web server, it is arguably the template for many of its competitors and many of its symbionts. It is the 800 pound gorilla of web infrastructure.
Programming distributed systems is hard. Programming systems that do a lot of different things simultaneously is hard. Programming long-lived processes is hard. So a trick (and I should acknowledge up front that it’s a good trick) that Apache and its brethren use is the one-process-per-connection architecture (or, in some products, one-thread-per-connection). The idea is that you have a control process and a pool of worker processes. The control process designates one of the worker processes to listen for a new connection, while the others wait. When a new connection comes in, the worker process accepts the connection and notifies the control process, who hands off responsibility for listening to one of the other waiting processes from the pool (actually, often this handshake is handled by the OS itself rather than the control process per se, but the principle remains the same). The worker then goes about actually reading the HTTP request from the connection, processing it, sending the reply back to the client, and so on. When it’s done, it closes the connection and tells the control process to put it back into the pool of available worker processes, whence it gets recycled.
This is actually quite an elegant scheme. It kills several birds with one stone: the worker process doesn’t have to worry about coordinating with anything other than its sole client and the control process. The worker process can operate synchronously, which makes it much easier to program and to reason about (and thus to debug). If something goes horribly wrong and a particular HTTP request leads to something toxic, the worker process can crash without taking the rest of the world with it; the control process can easily spawn a new worker to replace it. And it need not even crash — it can simply exit prophylactically after processing a certain number of HTTP requests, thus mitigating problems due to slow storage leaks and cumulative data inconsistencies of various kinds. All this works because HTTP is a stateless RPC protocol: each HTTP request is a universe unto itself.
Given this model, it’s easy to see where the connections-are-expensive meme comes from: a TCP connection may be cheap, but a process certainly isn’t. If every live connection needs its own process to go with it, then a bunch of connections will eat up the server pretty quickly.
And, in the case of HTTP, the doctrine of statelessness is the key to scaling a web server farm. In such a world, it is frequently the case that successive HTTP requests have a high probability of being delivered to different servers anyway, and so the reasoning goes that although some TCP connects might be technically redundant, this will not make very much difference in the overall user experience. And some of the most obvious inefficiencies associated with loading a web page this way are addressed by persistent HTTP: when the browser knows in advance that it’s going to be fetching a bunch of resources all at once from a single host (such as all the images on a page), it can run all these requests through a single TCP session. This is a classic example of where optimization of a very common special case really pays off.
The problem with all this is that the user’s mental model of their relationship with a web site is often not stateless at all, and many web sites do a great deal of work in their presentation to encourage users to maintain a stateful view of things. So called “Web 2.0” applications only enhance this effect, first because they blur the distinction between a page load and an interaction with the web site, and second because their more responsive Ajax user interfaces make the interaction between the user and the site much more conversational, where each side has to actively participate to hold up their end of the dialog.
In order for a web server to act as a participant in a conversation, it needs to have some short-term memory to keep track of what it was just talking to the user about. So after having built up this enormous infrastructure predicated on a stateless world, we then have to go to great effort and inconvenience to put the state back in again.
Traditionally, web applications keep the state in one of four places: in a database on the backend, in browser cookies, in hidden form fields on the page, and in URLs. Each of these solutions have distinct limitations.
Cookies, hidden form fields, and URLs suffer from very limited storage capacity and from being in the hands of the user. Encryption can mitigate the latter problem but not eliminate it — you can ensure that the bits aren’t tampered with but you can’t ensure that they won’t be gratuitously lost. These three techniques all require a significant amount of defensive programming if they are to work safely and reliably in any but the most trivial applications.
Databases can avoid the security, capacity and reliability problems with the other three methods, but at the cost of reintroducing one of the key problems that motivated statelessness in the first place: the need for a single point of contact for the data. Since the universe is born anew with each HTTP request, the web server that receives the request must query the database each time to reconstruct its model of the session, only to discard it again a moment later when request processing is finished. In essence, the web server is using its connection to the database — often a network connection to another server external to itself — as its memory bus. The breathtaking overhead of this has lead to a vast repertoire of engineering tricks and a huge after-market for support products to optimize things, in the form of a bewildering profusion of caches, query accelerators, special low-latency networking technologies, database clusters, high-performance storage solutions, and a host of other specialty products that frequently are just bandaids for the fundamental inefficiencies of the architecture that is being patched. In particular, I’ve been struck by the cargo-cult-like regard that some developers seem to have for the products of companies like Oracle and Network Appliance, apparently believing these products to possess some magic scaling juju that somehow makes them immune to the fundamental underlying problems, rather than merely being intensely market-driven focal points for the relentless incremental optimization of special cases.
(Before people start jumping in here and angrily pointing out all the wonderful things that databases can do, please note that I’m not talking about the many ways that web sites use databases for the kinds of things databases are properly used for: query and long term storage of complexly structured large data sets. I’m talking about the use of a database to hold the session state of a relatively short-term user interaction.)
And all of these approaches still impose some strong limitations on the range of applications that are practical. In particular, applications that involve concurrent interaction among multiple users (a very simple example is multi-user chat) are quite awkward in a web framework, as are applications that involve autonomous processes running inside the backend (a very simple example of this might be an alarm clock). These things are by no means impossible, but they definitely require you to cut against the grain.
Since the range of things that the web does do well is still mind bogglingly huge, these limitations have not been widely seen as pain points. There are a few major applications that fundamentally just don’t work well in the web paradigm and have simply ignored it, most notably massively multiplayer online games like World of Warcraft, but these are exceptions for the most part. However, there is some selection bias at work here: because the web encourages one form of application and not another, the web is dominated by the form that it favors. This is not really a surprise. What does bother me is that the limitations of the web have been so internalized by the current generation of developers that I’m not sure they are even aware of them, thus applications that step outside the standard model are never even conceived of in the first place.
Just consider how long it has taken Ajax to get traction: “Web 2.0” was possible in the late 1990s, but few people then realized the potential that was latent in Javascript-enabled web browsers, and fewer still took the potential seriously (notably, among those who did is my long time collaborator and business associate, Doug Crockford, instigator of the JSON standard and now widely recognized, albeit somewhat retroactively, as a Primo Ajax Guru). That “Web 2.0” happened seven or eight years later than it might otherwise have is due almost entirely to widespread failure of imagination. Doug and I were founders of a company, State Software, that invented a form of Ajax in all but name in 2001, and then crashed and burned in 2002 due, in large part, to complete inability to get anybody interested (once again, You Can’t Tell People Anything).
Back in The Olden Days (i.e., to me, seems like yesterday, and, to many of my coworkers, before the dawn of time), the canonical networked server application was a single-threaded Unix program driven by an event loop sitting on top of a call to select(), listening for new connections on a server socket and listening for data I/O traffic on all the other open sockets. And that’s pretty much how it’s still done, even in the Apache architecture I described earlier, except that the population of developers has grown astronomically in the mean time, and most of those newer developers are working inside web frameworks that hide this from you. It’s not that developers are less sophisticated today — though many of them are, and that’s a Good Thing because it means you can do more with less — but it means that the fraction of developers who understand what they’re building on top of has gone way down. I hesitate to put percentages on it, lacking actual quantitivate data, but my suspicion is that it’s gone from something like “most of them” to something like “very, very few of them”.
But it’s worth asking what would happen if you implemented the backend for a web application like an old-fashioned stateful server process, i.e., keep the client interacting over the same TCP connection for the duration of the session, and just go ahead and keep the short-term state of the session in memory. Well, from the application developer’s perspective, that would be just terribly, terribly convenient. And that’s the idea behind Elko, the server and application framework this series of posts is concerned with. (Which, as mentioned in Part I, I’m now unleashing on the world as open source software that you can get here).
Now the only problem with the aforementioned approach, really, is that it blows the whole standard web scaling story completely to hell — that and the fact that the browser and the rest of the web infrastructure will try to thwart you at every turn as they attempt to optimize that which you are not doing. But let’s say you could overcome those issues, let’s say you had tricks to overcome the browser’s quirks, and had an awesome scaling story that worked in this paradigm. Obviously I wouldn’t have been going on at length about this if I didn’t have a punchline in mind, right? That will be the substance of Part III tomorrow.
October 17, 2008
The Tripartite Identity Pattern
One of the most misunderstood patterns in social media design is that of user identity management. Product designers often confuse the many different roles required by various user identifiers. This confusion is compounded by using older online services, such as Yahoo!, eBay and America Online, as canonical references. The services established their identity models based on engineering-centric requirements long before we had a more subtle understanding of user requirements for social media. By conjoining the requirements of engineering (establishing sessions, retrieving database records, etc.) with the users requirements of recognizability and self-expression, many older identity models actually discourage user participation. For example: Yahoo! found that users consistently listed that the fear of spammers farming their e-mail address was the number one reason they gave for abandoning the creation of user created content, such as restaurant reviews and message board postings. This ultimately led to a very expensive and radical re-engineering of the Yahoo identity model which has been underway since 2006.
Consistently I’ve found that a tripartite identity model best fits most online services and should be forward compatible with current identity sharing methods and future proposals.
The three components of user identity are: the account identifier, the login identifier, and the public identifier.
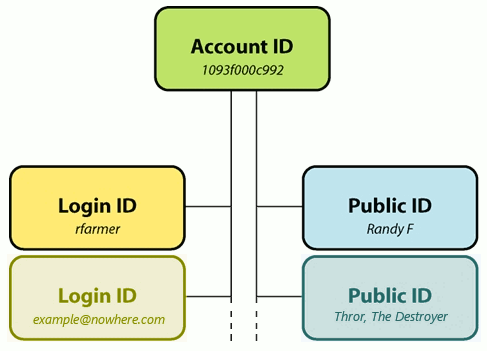
Account Identifier (DB Key)
From an engineering point of view, there is always one database key – one-way to access a user’s record – one-way to refer to them in cookies and potentially in URLs. In a real sense he account identifier is the closest thing the company has to a user. It is required to be unique and permanent. Typically this is represented by a very large random number and is not under the user’s control in any way. In fact, from the user’s point of view this identifier should be invisible or at the very least inert; there should be no inherent public capabilities associated with this identifier. For example it should not be an e-mail address, accepted as a login name, displayed as a public name, or an instant messenger address.
Login Identifier(s) (Session Authentication)
Login identifiers are necessary create valid sessions associated with an account identifier. They are the user’s method of granting access to his privileged information on the service. Historically, these are represented by unique and validated name/password pairs. Note that the service need not generate its own unique namespace for login identifiers but may adopt identifiers from other providers. For example, many services except external e-mail addresses as login identifiers usually after verifying that the user is in control of that address. Increasingly, more sophisticated capability-based identities are accepted from services such as OpenID, oAuth, and Facebook Connect; these provide login credentials without constantly asking a user for their name and password.
By separating the login identifier from the account identifier, it is much easier to allow the user to customize their login as the situation changes. Since the account identifier need never change, data migration issues are mitigated. Likewise, separating the login identifier from public identifiers protects the user from those who would crack their accounts. Lastly, a service could provide the opportunity to attach multiple different login identifiers to a single account — thus allowing the service to aggregate information gathered from multiple identity suppliers.
Public identifier(s) (Social Identity)
Unlike the service-required account and login identifiers, the public identifier represents how the user wishes to be perceived by other users on the service. Think of it like clothing or the familar name people know you by. By definition, it does not possess the technical requirement to be 100% unique. There are many John Smiths of the world, thousands of them on Amazon.com, hundreds of them write reviews and everything seems to work out fine.
Online a user’s public identifier is usually a compound object: a photo, a nickname, and perhaps age, gender, and location. It provides sufficient information for any viewer to quickly interpret personal context. Public identifiers are usually linked to a detailed user profile, where further identity differentiation is available; ‘Is this the same John Smith from New York that also wrote the review of the great Gatsby that I like so much?’ ‘Is this the Mary Jones I went to college with?’
A sufficiently diverse service, such as Yahoo!, may wish to offer multiple public identifiers when a specific context requires it. For example, when playing wild-west poker a user may wish to present the public identity of a rough-and-tumble outlaw, or a saloon girl without having that imagery associated with their movie reviews.
Update 11/12/2008: This model was presented yesterday at the Internet Identity Workshop as an answer to many of the confusion surrounding making the distributed identity experience easier for users. The key insight this model provides is that no publicly shared identifier is required (or even desirable) to be used for session authentication, in fact requiring the user to enter one on a RP website is an unnecessary security risk.
Three main critiques of the model were raised that should be addressed in a wider forum:
- There was some confusion of the scope of the model – Are the Account IDs global?
I hand modified the diagram to add an encompassing circle to show the context is local – a single context/site/RP. In a few days I’ll modify the image in this post to reflect the change.
- The term “Public Identity” is already in use by iCards to mean something incompatible with this model.
I am more than open to an alternative term that captures this concept. Leave comments or contact me at randy dot farmer at pobox dot com.
- Publically sharable capability-based identifiers are not included in this model. These include email addresses, easy-to-read-URLs, cel phone numbers etc.
There was much controversy on this point. To me, these capability based identifiers are outside the scope of the model, and generating them and policies sharing them are withing the scope of the context/site/RP. Perhaps an interested party might adopt the tripartite pattern as a sub-pattern of a bigger sea of identifiers. My goal was not to be all encompassing, but to demonstrate that only three identifiers are required for sites that have user generated content, and that no public capability bound ID exchange was required. RPs should only see a the Public ID and some unique key for the session that grants permission bound access to the user’s Account.