Posts filed under "Lessons Learned"
February 18, 2026
Adventures In LLM Land, With Thoughts On The AI Revolution
For the past year and a half or so I’ve been experimenting with AI tools for software development. This began with a single, small personal project, but has now grown to encompass a couple more very large personal projects. Hopefully, this means I will soon have some cool new stuff to unleash upon an unsuspecting world, but no promises before shipping. In my working life, my whole team has begun incorporating these tools as an increasingly central part of our regular software development workflow. At this point I’m completely convinced that this is just the way software development is going to be done henceforth, at least until the next turn of the paradigmatic wheel (though at the pace things are going, this could be any day now). This post is an attempt to summarize what I’ve learned and my thoughts about it.
There’s an emerging practice that I’ve been hearing a lot of developers refer to as “vibe coding”. This is both a terrible piece of jargon and a disappointingly sloppy way of approaching things. Recently I’ve also started encountering more and more people talking about “agentic” development. Possibly this terminology shift has to do with the fact that these tools make it easy to have multiple balls in the air at once, leading you to have multiple independent entities (“agents”!) doing work on your behalf at the same time, but I have a sneaking suspicion it may just be folks trying to sound more serious and respectable than “vibe coding” suggests.
My experience has been that, rather than letting you be lazy (which can be either an accusation or a touted payoff, depending on whether you are talking to a critic or an enthusiast), getting the maximum benefit out of these tools has taken a surprising amount of discipline. It’s just that the discipline required is very different from what you need for traditional programming.
As I’ve been recounting my AI coding adventures to friends and co-workers, it has slowly dawned on me that a lot of what I’ve been learning probably applies to a much broader range of applications than just software development. So I’m going to attempt to articulate this broader view in the hope that it might make a useful contribution to the wider conversation that pretty much everyone by now has been having about AI, its meaning, consequences, and proper role in human civilization. I’m increasingly dismayed by the “let’s sprinkle magic AI pixie dust on everything” mindset that seems to have consumed the souls of the current cohort of herd following executives, clueless bosses, and idiot marketeers.
A caveat: the following will be rather meandering with a lot of digressions. That’s just how I roll here; this is a personal blog that Randy and I write largely for our own psychic satisfaction, not some journal article submitted for academic peer review. If you just want the high order bits you can always skim, though you’ll probably miss a lot of the fun parts if you do that.
My first AI testbed project was a system to catalog and organize my family’s home library. Both Janice and I are book addicts. At this point I think our collection is somewhere north of 10,000 volumes, though how far north, at this point, I’m a bit scared to find out. A few years ago we moved into a bigger house, and in the unpacking we dumped many, many boxes of books straight onto shelves without any effort to sort or arrange them, because we needed to quickly get all those boxes off the floor just to have room to live in. This added an extra element of chaos to an already disorderly mess. Also, as part of this move we emptied out a self-storage unit that had been slowly and semi-invisibly accumulating books for about fifteen years, as a result of which we now have a 20-foot shipping container in our driveway packed wall-to-wall, floor-to-ceiling, with boxes of books. (How we could more than double our household square footage and still end up with less free space than we started with is another interesting story, but even more of a digression.)
Part of our problem is that used books have become incredibly cheap, thanks to various Friends Of The Fill-In-The-City Library fundraisers, the irresistible seduction of used bookstores, and the explosion of online dealers, who have taken advantage of database automation and cheap real estate in depressed parts of the country to cost effectively warehouse enormous inventories, even though e-books and the ongoing devaluation of reading in our society have rendered physical books increasingly valueless. All these enablers mean it is incredibly easy to accumulate a sizable book hoard at comparatively little effort or expense, which is actually terrible for us book addicts.
Setting aside the physical aspects of actually arranging to have shelves to put all these books on (I think I can now unpack and assemble an Ikea BILLY bookcase in about 10 minutes with my eyes closed) and repeatedly moving vast quantities of books around to sort them into some kind of rational order, if we want to catalog all of these books to know what we actually have and where it is, this whole situation poses a giant data entry nightmare.
If you’re a nerd, as everyone in my family certainly is, this was obviously a call for More Technology. And there’s an enormous amount of book scanning and book cataloging software out there. Alas, all of it appears to be one or more of (a) targeted at the aforementioned used book dealers, who are mostly interested in determining valuations and managing their warehouse inventories, rather than in maintaining a proper library, or (b) some kind of SaaS product where you have to pay by the month to rent your own data in the cloud while at the mercy of somebody who may at any moment go out of business, “pivot” and leave you orphaned, or have some deranged product manager redesign it all into unusability (all of which have happened to me, sometimes repeatedly, with various as-a-service products), or (c) so incredibly dumbed down in order to appeal to a consumer mass market as to have been rendered unsuitable for the task.
On the other hand, if you’re a nerd you’re not so deterred by the idea of building your own. It’s one of the hallmarks of nerd-dom — awareness that you can just make things. On the other other hand, I’m not particularly interested in spending the time and effort to master a bunch of the incidental building blocks that will necessarily be involved, such as putting a web-services frontend onto a database, dinking with all the CSS and HTML minutiae required for a proper UI, figuring out how and where to obtain things like ISBN data, or how to do optical data capture with a mobile app using the phone’s camera. I’m passingly familiar with all these things, but none of them to the degree needed to develop a clean, complete, integrated, end-to-end solution. So, a perfect foil for trying out some of these newfangled AI coding tools, I thought.
I started with the rough formula laid out by my friend Monica Anderson, who has been paying attention to this AI stuff far longer than almost anybody else I know. As best I can tell, in the subsequent year and half, her formula has become pretty much the de facto pattern that everybody doing “agentic” stuff uses. I don’t know if this is due to her direct influence or convergent evolution, but at any rate a lot of this will sound familiar to people who are already somewhere down this road.
For the AI bits, Monica at the time (the latter half of 2024) recommended using the Cline VSCode plugin with the Anthropic Claude 3.7 Sonnet model. These days she’s advocating Claude Code using the latest and greatest model, whatever that is; as of today’s writing this appears to be 4.6 Opus, which I have now switched to, but much of what I did was using older stuff. I suspect you’d get similar results with any of the other major tools for this sort of thing that various companies are promoting, but I was following a recipe, and the first time I cook something from a recipe I don’t deviate much from it. Tinkering comes later.
Just as an aside, a substantial majority of all of the AI coding tools I’ve looked at, including Cline, Copilot, Cursor, and Windsurf, seem to be based on VSCode or forks of it. I’m not the world’s biggest fan of VSCode, but this was one of those things where trying to cut against the grain seemed like it would be a bad idea. Stacked up against competing IDEs, I think VSCode is actually pretty good. It’s just that as an old school Unix hacker I have an ongoing beef with Integrated Development Environments per se — basically, they’re too damn integrated, but I digress again. Mercifully, Claude Code is a CLI tool, and that has made me much happier.
Following Monica’s recipe, I wrote a five page spec document that laid out the problem and described the shape of the desired solution, including a fairly concrete outline of the kind of system I wanted. There were three components:
- A backend catalog database, fronted by a web-accessible service API running on a computer entirely under my control (which is to say, no cloud entanglements, or at least none that can’t be replaced by a competitor on a moment’s notice).
- A browser-based web app for displaying, searching, and maintaining the catalog, including the ability to manually enter and update catalog entries.
- A mobile app for scanning books, looking up the relevant metadata from online sources, and from that generating catalog entries and storing them into the database. I want this app to be able to (in order of sophistication) scan ISBN barcodes, OCR ISBNs as text if the book predates such barcodes (ISBNs and their barcodes were standardized at the same time, but it took a few years longer for the bar codes themselves to become ubiquitous), or OCR the author/title text from the book’s cover or title page if the book predates ISBNs (ISBNs date from around 1970, and many of our books are older than that). Also, it should have a manual data entry interface to correct the inevitable errors that will no doubt be present in the available online data sources.
For genuinely weird stuff that’s too exotic to be scanned automatically (and there definitely will be such cases, given some of the volumes in our collection), I’d prefer the fully manual data entry fallback to be the web app, where I get to use a proper keyboard, rather than trying to enter it on my phone as if it was a tweet or something. In the case of very old books, we might have to resort to all manner of obscure clues to figure out what a particular volume actually is. I don’t think there’s a good payoff for the engineering effort to automate these edge cases, and I highly doubt that AI magic pixie dust is going to come our rescue here. At least not this year.
A lot of this spec detailed the kinds of information I wanted to capture and how I wanted to be able to organize it. I was also a bit more prescriptive than was probably strictly necessary with respect to a few platform choices, not because I was convinced those were the very best ways to do things but so that whatever the machine produced would be based on in things I was already reasonably familiar with (e.g., create a NodeJS express app for the backend server, use SQLite for the database, and so on). These choices were so that I could assess what had been produced and tell the machine to fix things I didn’t like. All of this was placed in a document called library.md.
I decided to begin with the backend/web-app combo, on the theory that this entrained less exotic weird stuff. Per Monica’s advice, the first prompt to the AI was "read library.md", followed by "create the web app and database backend just described", and we were off to the races. There followed a couple minutes of the screen twitching and flashing, and then, boom! Something came up in my web browser.
Instant software! But did it work? Well… sort of?
The machine did produce a web app that presented tables of stuff and an interface for creating and editing entries, but there were lots and lots of things wrong with it. The wrong things fell into two broad categories: (a) things that just didn’t work, and (b) bad UX and functionality decisions.
A few people I know have likened these tools to a junior programmer who your team hired straight out of school: someone who is super smart, very knowledgeable about All The Latest Things The Cool Kids Are Using, and energetic in the way that only naive young people can be, but also prone to leaping before they look and completely lacking in the kinds of common sense and taste that come with having spent a few years in the trenches.
This is pretty much consistent with my experience. It really is like managing a flock of recent MIT grads with masters degrees in computer science but no real world work experience. Fortunately for me, managing energetic, scary smart, but absurdly naive developers is something I’ve done previously in my career with reasonably good success, so I’m pretty comfortable with this as a process. In a lot of ways this is better; I’ve always found the engineering-management-as-software-development-at-a-higher-level-of-abstraction mindset very enjoyable and satisfying, but now you can do it without HR procedures or organizational politics.
So it took only the briefest time to generate a backend server with its associated database and a bare bones web UI that talked to it. Then I proceeded to spend the next two months of my spare time coaxing and prodding the fool thing to get the basic UX to be sane and the basic functionality to work properly. Things like: “when you update one field of a record, don’t change any of the other fields”, or “when you have several different related pages on a site all displaying textual data, they should all use the same font”, or “when you make a change to the code to add or fix a feature, all the other stuff that previously worked should continue to work, and in the same way as before”. It all eventually got working to my satisfaction, but the exercise was aggravating and tedious. Nevertheless, on net it all took considerably less of my time than doing all that stuff on my own would have; it’s just I would have made completely different mistakes and gone down completely different blind alleys. Though I successfully reached my goal, by the end I was quite ready to put the whole thing aside for a while and take a break from dueling with the bot.
A month or two later I was upgrading our household internet, switching from Comcast Business to AT&T Fiber — even though when we’d gotten Comcast in the first place because I’d sworn to never again do business with AT&T, they came in and offered me 10 times the bandwidth at half the price so I caved. The one hard requirement was that I needed a static IP address, which seems to be a weird and unusual service request even though I consider any internet hookup without one to be broken. Nevertheless, they were able to accommodate me “for a small monthly fee” once my AT&T rep found the right place to poke their system. I have a little FreeBSD box that has been our reliable inbound network gateway for years, and since the only thing that would be different with the new network provider was literally what the IP address itself was, I figured switching this over should be straightforward.
Ha. Those whom the gods would destroy they first make mad.
We got the AT&T fiber connection and router installed, configured everything to match the local network that all our devices already understood, and everything seemed to work. You could browse the web, my laptop could send and receive email, I could SSH back and forth amongst the various excessively numerous computers in our house, my son could play World of Warcraft, and so on. Hunky dory. All that remained was setting up that static connection, which should have been simple: Unplug the ethernet cable between the FreeBSD box and the Comcast router, reconfigure the FreeBSD box’s IP address, then plug the ethernet cable into the AT&T router. Nope.
It appeared I could make outward connections from the FreeBSD box to the rest of the world and I could access the external IP address from our LAN, but the rest of the world couldn’t see it. From the outside I couldn’t SSH to it, I couldn’t even ping it. What to do? Well, I’d been through an exercise very much like this before, back in the previous millennium when I got the very first AT&T (well, PacBell, but, you know…) DSL connection in my part of Palo Alto. It took six months of them fiddling around to get it all to work right, with them the whole while insisting that everything was fine until I brought them the next piece of evidence that it was, in fact, not fine, at which point they’d fiddle around some more and pronounce that, yes, ok, it wasn’t working before, but we fixed that and now everything is fine. Lather rinse repeat. They had to do all kinds of things to make it work, up to and including replacing all of the outside telephone wiring for my entire neighborhood when the wires turned out to be a bunch of ancient, rotted crap. Eventually they made it work, but until they did, every time I complained, the first thing they’d do was run some kind of remote connectivity test from their central office that always said everything was all working properly, even when it wasn’t. So when my new connection didn’t seem to be working right, I was wise to their game — obviously they’d made some kind of configuration error on their end or something. This time, when I called up AT&T and complained and they did their remote test and of course it said all was fine, I totally didn’t believe them, up until the service tech on the call recited to me the MAC address off the ethernet NIC on my FreeBSD box, which he had just read remotely. Oh. At which point my sense of reality seemed to shimmer a little. OK, the problem really is me. Hmm. There then followed days of Googling, going down blind alleys, testing various hypotheses. I found lots of websites very confidently stating that when this kind of failure happened the problem was definitely X and what you do about it was definitely Y, and they were always, always wrong.
It was then that I said, let’s ask the AI, it couldn’t possibly make things worse. I fired up Claude. The dialog went something like this:
Me: I have this networking problem <explanation of networking problem>. What do I do?
Claude: Type ifconfig and show me the output.
I think: yeah, that’s where I started too…
Me: <ifconfig output>
Claude: Type netstat and show me the output.
I think: yeah, and that also…
Me: <netstat output>
Claude: Type netstat -r and show me the output.
I think: dude, I’ve been down this road already…
Me: <netstat -r output>
Claude: You need to adjust your routing tables as follows: sudo route ...
Me: That’s obvious nonsense and can’t possibly work. <Tightly reasoned explanation of why it was obvious nonsense and couldn’t possibly work.>
Claude: You’re absolutely right! But I really think it’s this routing thing.
Sighing, I type in the route command to my FreeBSD command line.
Me: OK, I entered that route command.
Claude: Check if it’s now working.
I SSH to an offsite machine that I have an account on, and from there ping the new IP address. It works. I try SSHing to the FreeBSD box. That works too.
Damn.
Me: That worked! Why did that work?
Claude: <a paragraph of text explaining why it was the right thing to do>
Suddenly my mental model of what was going on shifted, I understood exactly what had been wrong, why I had been wrong about it, and why the routing tweak was the right fix. It all made sense. The world came back into focus.
This had me feeling quite a bit better about Claude’s eptness at dealing with subtle and confusing problems, so I decided to risk another foray into using it to actually create software. I told it to produce a first cut of the iPhone book scanner app. Once again, this took it about 5 minutes. At the time, none of the AI tooling I’d been using was integrated with Xcode, Apple’s IDE for iOS and Mac, which meant Claude could generate the code but it couldn’t actually try things out. So I fired up Xcode and was reminded that my installation was about five years out of date and my Apple developer account had expired. After a time consuming exercise in getting that all updated, I tried to build and install the code, but this failed miserably.
It turned out that the issue was another manifestation of out-of-dateness: my credentials and whatnot needed to be synced back up with the modern state of the world. Fortunately, there didn’t seem to be any actual build problems with the app code per se. The biggest complication in getting a successful build was all the certificate signing and permissions tweaking required to enable me to actually install the resulting app onto my physical hardware — and I needed to test with the actual hardware since the app would be using the phone’s camera. Configuring all this crap has always been a rough spot in the Apple tooling ecosystem, not because their technology for securing access to the phone is flawed (it seems to be quite well thought out, actually), but because their tooling is confusing and execrably documented (I’ll spare you my whole long rant about modern tech writing fads, since it’s another digression on a digression). So I asked Claude to walk me through it, and it just did. The whole song and dance was fussy, highly non-intuitive, and ridiculously complicated, but by following Claude’s step-by-step instructions precisely the whole thing went off without a hitch.
I plugged my phone into my Mac, hit the button to build, install, and launch the app, and moments later my phone was displaying the view from its camera and asking to be pointed at a book. I grabbed a book at random from the shelf next to my desk and held it up to the phone, which immediately beeped and replaced the display with a nicely formatted summary of the book’s title, author, and publication data, along with a crisp thumbnail of the cover art. I involuntarily burst out laughing, loudly enough to cause my son to come running in from the other room to see if I was OK. The thing had worked perfectly on the first try. This was magic.
What differentiated this from my first exercise in AI coded software was that the target was defined in almost purely functional terms: do this. The thing I wanted done was technically very difficult, but essentially straightforward, whereas the earlier thing was technically very pedestrian but contained a whole lot more stuff that needed to be just so for me to to be happy with it.
When you write a spec for something you intend to create yourself, you end up leaving out a lot of details, especially aesthetic details (both the aesthetics of how the thing will appear on the outside as well as the engineering aesthetics of how it will be put together on the inside). You can get away with omitting that stuff because you’re going to automatically follow your own instincts anyway as you proceed to implement it. You almost can’t help yourself. Very often you might not even realize that you left out details because you just create things the way you create things and the result is pretty much what you were expecting. On the other hand, if you’ve ever had to specify something for somebody else to implement, you’ve no doubt had the experience of getting results very different from what you wanted.
There’s a famous line from the world of politics:
- “I can explain it to you, but I can’t understand it for you.”
I’ve heard this attributed to various people, but since it’s one of those highly quotable sound bites that’s been spread around so much (often with mutations) I found it a little tricky to track down for sure where it came from. As best I’ve been able to dig up, it seems to have originated (in slightly less eloquent form) with former New York City mayor Ed Koch. I had remembered it as some physicist testifying in front of a Senate committee about funding for some Big Science project, but that may just be narrative bias coming into play since it makes the story better. Or it could be that I’m just having a hard time imagining Ed “I am the mayor” Koch saying something clever and insightful.
Anyway.
The idea here is that although someone else can give you an explanation of something, the task of internalizing that explanation and developing an understanding of what was explained is ultimately up to you. Nobody else can do that for you – it needs to be your understanding.
I think this insight is itself directly applicable to the AI experience, but it also inspired for me a slightly parallel variant:
- “The AI can make things for you, but it can’t want things for you.”
A lot of AI skeptics and critics have commented that using AI for artistic endeavors generally produces things that range somewhere between mediocre and terrible. And they’re not wrong. Creative expression is an almost pure manifestation of the creator’s wants and desires. When you write a story, for example, every element of it at every level, from the shape of the overall plot down to the structure and word choice of individual sentences, is a reflection of what you want those things to be. You have to be the one who determines what all those things are, based on your own desires. Now, you might still produce a mediocre or terrible story yourself because you’re bad at this in some way, but it still comes from your choices about what you wanted at each step. You can’t outsource that wanting to somebody else because then you’ll get what that somebody else wants and then it’s their story. And anyway the AI doesn’t want anything. At best, the AI can try to guess what you want. If what you want is vague and mushy then its guess will be vague and mushy too, and you’re going to get the kind of slop that everybody is criticizing. On the other hand, if what you want is not vague and mushy, then you have to communicate this with completeness and precision, at which point you don’t need the AI to write the story for you because you’ve just written it yourself.
I’ve seen a number of AI commentors quite appropriately point to David McCullough’s lovely aphorism: “Writing is thinking.” To an astonishing degree, the idea a lot of people have that writing is “just putting your thoughts into words” is a mischaracterization, as if the words were already sitting there in your head and just needed to be recorded. It is the very act of generating the words that constitutes the mental process that solidifies the ideas that the words are expressing. If you’re like me, you also do a lot of fiddling and editing after the first words have come out of your fingers, as you try to make what you’re saying clear, not only to others but also to yourself. And that clarification is really clarification of the very thoughts being expressed. I’m certainly not the first person to quip “I don’t really know what I think until I hear what I say”, but I do quote that line a lot. I find that writing, editing, and figuring stuff out all are pretty entangled. You can’t outsource your writing because you can’t outsource your thinking.
Well, I should qualify that last assertion. Of course you can outsource your thinking, but this amounts to handing control of your mind over to someone else: what you get is what they want. Certainly the world is filled with people who would be very happy to do your thinking for you, but it’s almost certainly a bad idea to let them. And, as I said, the AI itself doesn’t want anything. Or rather, it might seem to want things, but those largely reflect the wants of whoever set it up. Which might align with what you want too, but probably not. Or, much likelier, it might be something that whoever set the AI up just doesn’t care about, so you’ll get some random crap. We seem to be seeing a lot of that sort of thing these days too.
Compared to a work of art, however, a piece of software is much more of a functional mechanism than a pure act of expression. Certainly the act of coding will often have a significant expressive element, but there are also critical parts of it that can be evaluated on a fairly objective works/doesn’t work basis. The big challenge in using AI tools for software creation is maintaining the proper division of labor between you and the machine. The machine’s job is doing all the heavy lifting involved in making the mechanical parts (which for a human could consume hours or days or even years of somebody’s life to implement), while your job is to do the expressive parts. And even though AI is somewhat exotic at this point, this pattern of technology use fits a lot of our existing ways to doing things. I know a very talented sculptor who uses CAD tools, NC-machining, and 3D printers to fabricate her work, and nobody would argue that the things she makes this way are not her creations.
This gets back to my earlier comment about wanting. In a world with AI, your job is to want things. The key to successfully creating things is the ability to know or figure out what you want, and then the ability to express this. Both the knowing and the expression are hard, and the sad truth is that the ability to do them well is unevenly distributed among the human population, but they’re still 100% human. Further, if you’re interested in more than just yourself (and I hope you are), you need to be able to want things that your customers or clients or audience or the world at large will want, even (or especially) if they don’t know it yet. The ability to consistently do that is very rare indeed (vanishingly few of us are Steve Jobs, for example), and nothing about AI seems likely to soon change this. Note that this formulation goes beyond AI assisted software development. I think it applies equally well to using AI for anything.
These days I’m seeing a lot of irritation with the corporate world’s seemingly relentless drive to blindly stuff AI into just about everything. I share people’s annoyance, but a lot of the complaining seems to frame it as “this stuff is stupid and nobody wants it, so AI is bad”. I agree with the premise but not the conclusion. I think we’re in the midst of one of those once-in-a-generation technological upheavals that always takes the
conventionally minded among the executive class (which is to say, most of them) by surprise. The current tidal wave of foolishness reflects the general unpreparedness that people who are highly adapted to the status quo tend to be prone to when confronted with something outside their experience. It’s basically Kuhn, only for business. I’m old enough to have seen this pattern play out repeatedly over the course of my career. It happened when minicomputers wiped out the mainframe business, then again when personal computers wiped out the minicomputer business. It happened very dramatically with the advent of the Internet and the World Wide Web — remember all those stupid pets.com and MCI ads during the Superbowl back in the day, when “Internet!” was the magic pixie dust of the hour?
In the earliest days of the Internet takeoff, 1993- or 1994-ish, when everyone in the business world could see it was coming but it hadn’t really hit yet, there was an astonishing amount of stupid stuff being rolled out, with truly eye watering quantities of money behind it. It seemed like every few days you’d see another bizarre announcement of a joint venture or a “strategic initiative” from one or more giant companies in the telecommunications and media sectors. My business partners and I referred to this era as “The Dance of The Dinosaurs”, with the doomed incumbents frantically pairing off in unlikely combinations in hopes of finding the DNA mix to survive the New World Order. I once facetiously suggested to my colleagues that we should pitch a proposal to AT&T that was roughly: “You give us $150 million. We’ll do whatever the hell we feel like with it and you’ll never see your money ever again. This is basically the same deal you’ve been making with everybody else; our value-add proposition to you is that we promise we won’t tell anybody that you did this, so that, unlike your other ventures, you’ll be spared the public embarrassment when all the money is gone.” I sometimes wish we had at least made the attempt. I’m pretty sure they would have said no, but I’m entirely confident we would have ended up with some great stories before they did.
The current era of ludicrous ferment around AI reminds me a lot of that time.
The important thing to keep in mind is that just because many of the people currently in charge of things lack a good mental model of what is possible and therefor do a bunch of dumb stuff, it doesn’t mean there isn’t a lot smart stuff on its way to us from the some of the less dumb people. Also, criticism of the dumb things shouldn’t be reflexively generalized. Some of the things that some of the less dumb people are about to do might also warrant criticism, but these things will need to be confronted on their own terms for what they actually are, rather than regarding them as just more of the same. Plus, a lot of the criticism I see of the dumb stuff is also pretty dumb itself, which is easy to overlook if the thing being criticized is already self evidently stupid — somebody can correctly point out that a thing is bad, while at the same time giving a largely mistaken accounting of why it’s bad. For example, I’m about ready to start throwing dishes the next time I hear somebody say “stochastic parrot”.
Finally, I have an issue with the broad movement to inject AI into absolutely everything. As suspected by many who are concerned about AI consequences, one source of the AI push at a lot of companies is a desire to reduce costs by substituting AI for headcount. There is a Big Discussion to be had about the possible and likely economic disruptions that flow from this, but that’s not at the heart of what I want to focus on right now. And in any case that Big Discussion is already going on all around us with some vigor at the moment, so I’m going set the Very Important Questions aside for now on the theory that other people are already deeply engaged with those.
Instead, I want to give a warning about a possible misreading of what I just advocated a few paragraphs above.
If you’re a CEO, particularly if you’re the CEO of a big company, your control over what happens is largely indirect. You can issue arbitrary instructions to pretty much any employee to do particular things or to do things in a particular way, but micromanagement doesn’t scale. Direct command is generally limited to narrow interventions for specific purposes in special circumstances. Most likely, most of your company tends to operate pretty autonomously most of the time, even if the organization has a strict chain of command and you imagine that you run things as an iron fisted dictator. Instead, your main job consists of establishing a vision and a purpose, and a strategy to achieve these, and then trying to communicate all this to the rest of the company, so that people in different parts of the organization can align what they do without constantly having to explicitly coordinate with you or with each other. To the extent that you do exercise direct control, most of it still runs through the senior management team, to whom you have delegated almost everything. A lot of CEOs aren’t very good at this, but that’s how it works. So, to summarize: you’re a person who (hopefully) has an idea in their head of what they want, which might be something big and complicated. You give general directions to a group of semi-autonomous actors who then go and try to do whatever it is, under your guidance. Does this pattern sound familiar?
If you’re a CEO, it may be pretty easy to fall into mapping what you do, and your relationship to your organization, to more or less the same model I articulated above for a human overseeing a flock of AI agents. From there it’s a pretty small step to thinking you can swap out humans for AIs in various boxes on your org chart. They sound like the same thing, right? I can see how this might be seductive, but it’s also likely to be a terrible mistake. The analogy breaks down because a CEO has to delegate the wanting of things to lower levels in the organizational hierarchy — one of the things you are delegating is not just the performance of tasks but judgement and taste. Even if you are brilliant as a CEO, you might well lack a deep sense of what’s good or bad in the realm of, say, graphic design or advertising strategy. Knowing what you want at one level of abstraction does not imply that you know what you should want at another level to get to your desired end state. In a complex organization, there may be many layers of recursively ramified desire unfolding before reaching the point of doing something concrete, like writing a piece of code or purchasing a building or moving things around in a warehouse or ordering parts to build some widget.
My offhand quip above that “most of us aren’t Steve Jobs” hints at another dimension of what is going on here.
If you aren’t a Steve Jobs, you probably don’t have a very strong product vision. It won’t do to tell your AI to “conceive of a product for our company that nobody has ever heard of but that lots of people will want when they do”. It’s too vague, and yet at the same time too anchored in the particulars of what your company is already doing. Instead, you have people for that. Maybe AIs will develop to where they can handle a directive of this sort, but at that point I think they’ve probably become people themselves and then we’re moving on to a whole new conversation. That’s certainly not where we are now nor where we are likely to be for the next couple of years.
If you are a Steve Jobs, it still takes a huge number of creative acts to translate your very strong product vision into an actual artifact that can be manufactured and sold, and no matter how good you are you do not have the breadth of talent to do all the things, and you absolutely don’t have the capacity for the sheer quantity of creative work that’s going to be involved. And this before we even get to the critical ancillary activities like marketing and advertising and branding. And then riding the wave of culture hacking you’re going to find your company doing if you’re ultimately successful.
Even a very conventional, run-of-the-mill business, like, say, a grocery store chain or an electric power utility, still has a lot of creative processes going on at many levels between the executive suite and the completely mechanical stuff on the ground. It seems likely to me that much of that mechanical stuff on the ground is destined to become automated, but this still leaves a lot of other stuff that you’re going to want some person in the driver’s seat for.
Returning to the theme I started with, my adventures with AI and what I’ve learned from it: We have been granted a giant lever, but we’re still very new at figuring out what to do with it.
I’m seeing a lot of social media traffic about what the current AI frenzy is doing to developers. My friend Perry Metzger says “the bulk of the programmers I know are giddy about AI coding”. That matches my own observations, of both the people around me and myself. At the same time, I’m also hearing a number of developers report feeling highly stressed by the situation — not, it’s important to note, by fear of job loss but by a compulsion they feel to be constantly feeding new tasks to their cloud of AI agents whose appetite for work seems bottomless. This isn’t exactly FOMO, but it feels psychologically related. I’m also seeing quite a few reports (mostly from AI critics and skeptics, but not entirely) of teams of developers holed up in an office or apartment somewhere, feverishly cranking around the clock with only the barest breaks to eat or nap, unable to pause or relax. This sounds more like the behavior of drug addicts. There have been times in my past when I also worked frantically around the clock in startup mode. However, in my case it was mostly because I was having a vast amount of fun doing what I was doing rather than the withdrawal pain I’d suffer if I didn’t get my next fix. I’d be a bit inclined to invoke Herb Stein’s Law here — if something cannot go on forever it will eventually stop — if it weren’t that the mode of eventually stopping might involve people doing serious harm to themselves.
I confess I do feel a little bit of this compulsive draw myself too, though I can also report that I’ve found that the way my cheapo Claude Pro account works naturally enforces a pleasant kind of work-life balance: it usually only takes me 20-30 minutes to prompt Claude Code to use up all of my account’s available capacity before it hits the built-in rate limit, at which point I have to wait for the next 5 hour window to open before I can do anything further with the thing — unless I spend money, of course, which is no doubt what they’re trying to stimulate, but I have so far resisted the siren call. In the meantime I write, or work on sorting the enormous book collection I mentioned at the start of this essay, or read, or do some photography, or work on a puzzle, or take a hike, or cook some dinner, or spend time with my family. This is just an artifact of Anthropic’s current billing model, so it’s almost certainly transient and will likely soon mutate as the capacity of their system grows, but it hints at an idea of what’s going on here and possibly how to cope with it.
We developers have been habituated to a world in which the major productivity bottleneck was our own capacity to write and debug code. Having that bottleneck suddenly get vastly wider while you’re in the midst of pushing hard against it is like stepping on the clutch and the gas pedal at the same time — likely to burn up the engine if you don’t catch yourself soon enough.
We need to learn how to accommodate ourselves to our new role, which is wanting things. It will help to have good taste and good judgement; in my experience the very best developers do tend to have both of these, though our industry certainly has no shortage of people who … don’t. As with every paradigm shift, the qualities that lead to success are going to change from what they historically were. This will be painful for the people who had the qualities the old world wanted but not the ones the new world wants, and we would do well to be compassionate to the folks who have difficulty with this transition, but in this regards AI is no different from any of the other twists and turns that have accompanied the progress of humanity. But don’t fall into the trap that thinking these qualities are fixed and immutable, that you are either one of the elect or you are not — a lot of what you are good at now follows from the habits of thought that you have learned and practiced, and most of you are capable of learning and practicing new habits of thought too.
Learn to be a good wanter.
August 5, 2021
February 7, 2017
Open Source Lucasfilm’s Habitat Restoration Underway
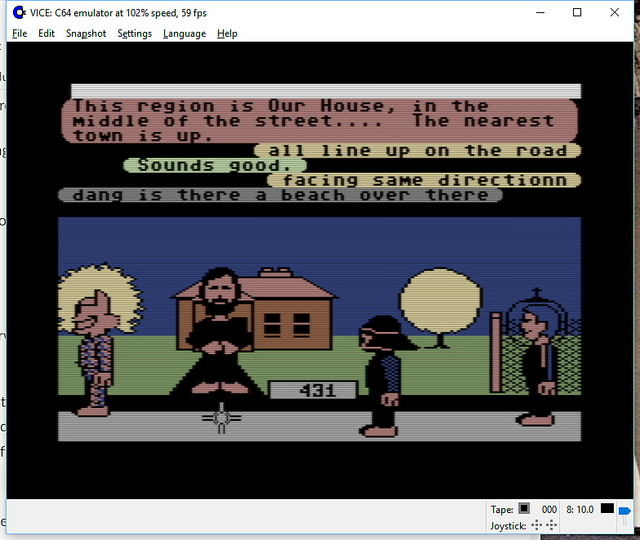
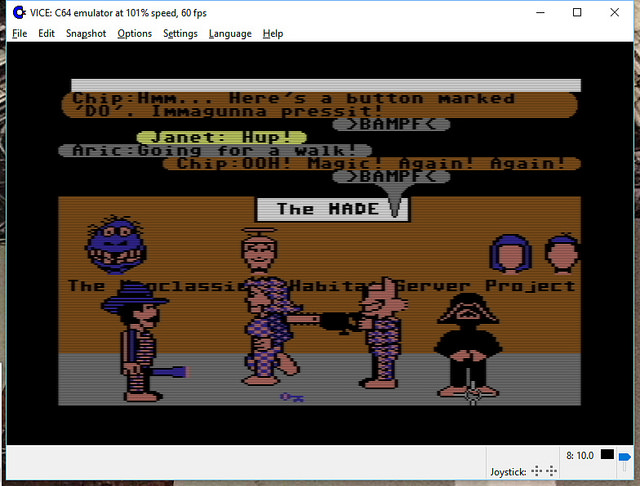
It’s all open source!
Yes – if you haven’t heard, we’ve got the core of the first graphical MMO/VW up and running and the project needs help with code, tools, doc, and world restoration.
I’m leading the effort, with Chip leading the underlying modern server: the Elko project – the Nth generation gaming server, still implementing the basic object model from the original game.
http://neohabitat.org is the root of it all.
http://slack.neohabitat.org to join the project team Slack.
http://github.com/frandallfarmer/neohabitat to fork the repo.
To contribute, you should be capable to use a shell, fork a repo, build it, and run it. Current developers use: shell, Eclipse, Vagrant, or Docker.
To get access to the demo server (not at all bullet proofed) join the project.
We’ve had people from around the world in there already! (See the photos)
http://neohabitat.org #opensource #c64 #themade
October 27, 2014
The Bureaucratic Failure Mode Pattern
When we try to take purposeful action within an organization (or even in our lives more generally), we often find ourselves blocked or slowed by various bits of seemingly unrelated process that must first be satisfied before we are allowed to move forward. Some of these were put in place very deliberately, while others just grew more or less organically, but what they often have in common, aside from increasing the friction of activity, is that they seem disconnected from our ultimate purpose. If I want to drive my car to work, having to register my car with the DMV seems like a mechanically unnecessary step (regardless of what the real underlying reason for it may be).
Note that I’m not talking about the intrinsic difficulty or inconvenience of the process itself (car registration might entail waiting around for several hours in the DMV office or it might be 30 seconds online with a web page, for example), but the cost imposed by the mere existence of the need to report information or get permission or put things in some particular way just so or align or coordinate with some other thing (and the concomitant need to know that you are supposed to do whatever it is, and the need to know or find out how). Each of these is a friction factor; the competence or user-friendliness of whatever necessary procedure is involved may influence the magnitude of the inconvenience, but not the fact of it. (Other recursive friction factors embedded in the organizations or processes behind these things may well figure into why many of them are in fact incompetently executed or needlessly complex or time consuming, but that is a separate matter.)
Over time, organizations tend to acquire these bits of process, the way ships accumulate barnacles, with the accompanying increase in drag that makes forward progress increasingly difficult and expensive. However, barnacles are purely parasitic. They attach themselves to the hull for their own benefit, while the ship gains nothing of value in return. But even though organizational cynics enjoy characterizing these bits of process as also being purely parasitic, each of those bits of operational friction was usually put there for some purpose, presumably a purpose of some value. It may be that the cost-benefit analysis involved was flawed, but the intent was generally positive. (I’m ignoring here for a moment those things that were put in place for malicious reasons or to deliberately impede one person’s actions for the benefit of someone else. These kinds of counter-productive interventions do happen from time to time, and while they tend to loom large in people’s institutional mythologies, I believe such evil behavior is actually comparatively rare – perhaps not that uncommon in absolute terms, but still dwarfed by the truly vast number of ordinary, well-intentioned process elements that slow us down every day.)
Because I’m analyzing this from a premise of benign intent, I’m going to avoid characterizing these things with a loaded word like “barnacles”, even though they often have a similar effect. Instead, let’s refer to them as “checkpoints” – gates or control points or tests that you have to pass in order to move forward. They are annoying and progress-impeding but not necessarily valueless.
We are forced to pass through checkpoints all the time – having to swipe your badge past a reader to get into the office (or having to unlock the door to your own home, for that matter), entering a user name and password dozens of times per day to access various network services, getting approval from your boss to take a vacation day, having to fill out an expense report form (with receipts!) to get reimbursed for expenses you have incurred, all of the various layers of review and approval to push a software change into production, having to get approval from someone in the legal department before you can adopt a new piece of open source software; the list is potentially endless.
Note that while these vary wildly in terms of how much drag they introduce, for many of them the actual amount is very little, and this is a key point. The vast majority of these were motivated by some real world problem that called for some tiny addition to the process flow to prevent (or at least inhibit) whatever the problem was from happening again. No doubt some were the result of bad dealing or of an underemployed lawyer or administrator trying to preempt something purely hypothetical, but I think these latter kinds of checkpoint are the exception, and we weaken our campaign to reduce friction by paying too much attention to them – that is, by focusing too much on the unjustified bureaucracy, we distract attention from the far larger (and therefore far more problematic) volume of justified bureaucracy.
Let’s just presume, for the purpose of argument, that each of the checkpoints that we encounter is actually well motivated: that it exists for a reason, that the reason can be clearly articulated, that the reason is real, that it is more or less objective, that people, when presented with the argument for the checkpoint, will find it basically convincing. Let’s further presume that the friction imposed by the checkpoint is relatively modest – that the friction that results is not because the checkpoint is badly implemented but simply because it is there. And yes, I am trying, for purposes of argument, to cast things in a light that is as favorable to the checkpoints as possible. The reason I’m being so kind hearted towards them is because I think that, even given the most generous concessions to process, we still have a problem: the “death of a thousand cuts” phenomenon.
Checkpoints tend to accumulate over time. Organizations usually start out simple and only introduce new checkpoints as problems are encountered – most checkpoints are the product of actual experience. Checkpoints tend to accumulate with scale. As an organization grows, it finds itself doing each particular operation it does more often, which means that the frequency of actually encountering any particular low probability problem goes up. As an organization grows, it finds itself doing a greater variety of things, and this variety in turn implies greater variety of opportunities to encounter whole new species of problems. Both of these kinds of scale-driven problem sources motivate the introduction of additional checkpoints. What’s more, the greater variety of activities also means a greater number of permutations and combinations of activities that can be problematic when they interact with each other.
Checkpoints, once in place, tend to be sticky – they tend not to go away. Partly this is because if the checkpoint is successful at addressing its motivating problem, it’s hard to tell if the problem later ceases to exist – either way you don’t see it. In general, it is much easier for organizations to start doing things than it is for them to stop doing things.
The problem with checkpoints is their cumulative cost. In part, this is because the small cost of each makes them seductive. If the cost of checkpoint A is close to zero, it is not too painful, and there is little motivation or, really, little actual reason to do anything about it. Unfortunately, this same logic applies to checkpoint B, and to checkpoint C, and indeed to all of them. But the sum of a large number of values near zero is not necessarily itself a value near zero. It can, instead, be very large indeed. However, as we stipulated in our premises above, each one of them is individually justified and defensible. It is merely their aggregate that is indefensible – there is nothing to tell you, “here, this one, this is the problem” because there isn’t any one which is the problem. The problem is an emergent phenomenon.
Any specific checkpoint may be one that you encounter only rarely, or perhaps only once. Consider, for example, all the various procedures we make new hires go through. When you hit such a checkpoint, it may be tedious and annoying, but once you’ve passed it it’s done with. Thereafter you really have no incentive at all to do anything about it, because you’ll never encounter it again. But if we make a large number of people each go through it once, there’s still a large multiplier, and we’ve still burdened our organization with the cumulative cost.
A problem of particular note is that, because checkpoints tend to be specialized, they are often individually not well known. Plus, a larger total number of checkpoints increases the odds in general that you will encounter checkpoints that are unknown or mysterious to you, even if they are well known to others. Thus it becomes easy for somebody without the relevant specialized knowledge to get into trouble by violating a rule that they didn’t even know to exist.
Unknown or poorly understood checkpoints increase friction disproportionately. They trigger various kinds of remedial responses from the organization, in the form of compliance monitoring, mandatory training sessions, emailed warning messages and other notices that everyone has to read, and so on. Each such checkpoint thus generates a whole new set of additional checkpoints, meaning that the cumulative frictions multiply instead of just adding.
Violation of a checkpoint may visit sanctions or punishment on the transgressor, even if the transgression was inadvertent. The threat of this makes the environment more hostile. It trains people to be become more timid and risk averse. It encourages them to limit their actions to those areas where they are confident they know all the rules, lest they step on some unfamiliar procedural landmine, thus making the organization more insular and inflexible. It gives people incentives to spend their time and effort on defensive measures at the expense of forward progress.
When I worked at Electric Communities, we had (as most companies do) a bulletin board in our break room where we displayed all the various mandatory notices required by a profusion of different government agencies, including arms of the federal government, three states (though we were a California company, we had employees who commuted from Arizona and Oregon and so we were subject to some of those states’ rules too), a couple of different regional agencies, and the City of Cupertino. I called it The Wall Of Bureaucracy. At one point I counted 34 different such notices (and employees, of course, were expected to read them, hence the requirement that they be posted in a prominent, common location, though of course I suspect few people actually bothered). If you are required to post one notice, it’s pretty easy to know that you are in compliance: either you posted it or you didn’t. But if you are required to post 34 different notices, it’s nearly impossible to know that the number shouldn’t be 35 or 36 or that some of the ones you have are out of date or otherwise mistaken. Until, of course, some government inspector from some agency you never heard from before happens to wander in and issue you a citation and a fine (and often accuse you of being a bad person while they’re at it). As Alan Perlis once said, talking about programming, “If you have a procedure with ten parameters, you probably missed some.”
In the extreme case, the cumulative costs of all the checkpoints within an organization can exceed the working resources the organization has available, and forward progress becomes impossible. When this happens, the organization generally dies. From an external perspective – from the outside, or even from one part of the organization looking at another – this appears insane and self-destructive, but from the local perspective governing any particular piece of it, it all makes sense and so nothing is done to fix it until the inexorable laws of arithmetic put a stop to the whole thing. A famous example of this was Atari, where by 1984 the combined scleroses effecting the product development process became so extreme that no significant new products were able to make it out the door because the decision making and approval process managed to kill them all before they could ship, even though a vast quantity of time and money and effort was spent on developing products, many of them with great potential. Few organizations manage to achieve this kind of epic self-absorption, though some do seem to approach it as an asymptote (e.g., General Motors). In practice, however, what seems to keep the problem under control, here in Silicon Valley anyway, is that the organization reaches a level of dysfunction where it is no longer able to compete effectively and it is supplanted in the marketplace by nimbler and generally younger rivals whose sclerosis is not as advanced.
The challenge, of course, is how to deal with this problem. The most common pathway, as alluded to above, is for a newer organization to supplant the older one. This works, not because the one organization is intrinsically more immune to the phenomenon than the other but simply due to the fact that because it is younger and smaller it has not yet developed as many internal checkpoints. From the perspective of society, this is a fine way of handling things; this is Schumpeter’s “creative destruction” at work. It is less fine from the perspective of the people whose money or lives are invested in the organization being creatively destroyed.
Another path out of the dilemma is strong leadership that is prepared to ride roughshod over the sound justifications supporting all these checkpoints and simply do away with them by fiat. Leaders like this will disregard the relevant constituencies and just cut, even if crudely. Such leaders also tend to be authoritarian, megalomaniacal, visionary, insensitive, and arguably insane – and, disturbingly often, right – i.e., they are Steve Jobs. They also tend to be a bit rough on their subordinates. This kind of willingness to disrespect procedure can also sometimes be engendered by dire necessity, enabling even the most hidebound bureaucracies to manifest surprising bursts of speed and effectiveness. A well known and much studied example of this phenomenon is the military, ordinarily among the stuffiest and most procedure bound of institutions, which can become radically more effective in times of actual war. In the first three weeks of American involvement in World War II, when we weren’t yet really doing anything serious, Army Chief of Staff George Marshall merely started carefully asking people questions and half the generals in the US Army found themselves retired or otherwise displaced.
A more user-friendly way to approach the problem is to foster an institutional culture that sees the avoidance of checkpoints as a value unto itself. This is very hard to do, and I am hard pressed to think of any examples of organizations that have managed to do this consistently over the long term. Even in the short term, examples are few, and tend to be smaller organizations embedded within much larger, more traditional ones. Examples might include Bell Labs during AT&T’s pre-breakup years, Xerox PARC during its heyday, the Lucasfilm Computer Division during the early 1980s, or the early years of the Apollo program. Each of these examples, by the way, benefited from a generous surplus of externally provided resources, which allowed them to trade a substantial amount of resource inefficiency for effective productivity. Surplus resources, however, tend also to engender actual parasitism, which ultimately ends the golden age, as all these examples attest.
The foregoing was expressed in terms of people and organizations, but essentially the same analysis applies almost without modification to software systems. Each of the myriad little inefficiencies, rough edges, performance draining extra steps, needless added layers of indirection, and bits of accumulated cruft that plague mature software is like an organizational checkpoint.
December 19, 2013
Audio version of classic “BlockChat” post is up!
On the Social Media Clarity Podcast, we’re trying a new rotational format for episodes: “Stories from the Vault” – and the inaugural tale is a reading of the May 2007 post The Untold History of Toontown’s SpeedChat (or BlockChattm from Disney finally arrives)
Link to podcast episode page[sc_embed_player fileurl=”http://traffic.libsyn.com/socialmediaclarity/138068-disney-s-hercworld-toontown-and-blockchat-tm-s01e08.mp3″]
August 26, 2013
Randy’s Got a Podcast: Social Media Clarity
![]()
I’ve teamed up with Bryce Glass and Marc Smith to create a podcast – here’s the link and the blurb:
Social Media Clarity – 15 minutes of concentrated analysis and advice about social media in platform and product design.
First episode contents:
News: Rumor – Facebook is about to limit 3rd party app access to user data!
Topic: What is a social network, why should a product designer care, and where do you get one?
Tip: NodeXL – Instant Social Network Analysis
August 23, 2013
Patents and Software and Trials, Oh My! An Inventor’s View
What does almost 20 years of software patents yield? You’d be surprised!
I gave an Ignite talk (5 minutes: 20 slides advancing every 15 seconds) entitled
“Patents and Software and Trials, Oh My! An Inventor’s View”
Here’s some improved links…
-
I’ve created ip-reform.org to support the “I Won’t Sign Bogus Patents” pledge.
-
Encourage your company to adopt Twitter’s Inventor’s Patent Agreement
-
Support the The EFF on Patent Reform – DefendInnovation.org has a proposal
-
Sequestration has delayed a bay area PTO office, support this bill
I gave the talk twice, and the second version is also available (shows me giving the talk and static versions of my slides…) – watch that here:
July 25, 2012
Forward looking statements
People say things to other people all the time that are misinterpreted or misunderstood; this is a normal part of life as a social animal. But this is especially true of things people say about the future, what the securities business calls “forward looking statements”. Statements about the future are marvelous sources of chaos and confusion because the future is intrinsically uncertain. The inevitable divergence between what someone said at one time and what actually happened at a later time invites all kinds of reinterpretation and second guessing and finger pointing, well beyond the usual muddle that is an ordinary part of human social interaction.
Because people in an organization are trying to coordinate purposeful and often complex tasks over time, forward looking statements make up a large fraction of intra-organizational communications, a larger fraction than I think is typical in purely social or familial interactions. Over the years I’ve learned that I often have to train people I’m working with on the distinction between three related but very different kinds of forward looking statements: plans, predictions, and promises. In my experience, somebody treating one of these as one of the others can be a significant generator of interpersonal discord and organizational dysfunction.
In particular we make a lot of these kinds of statements to people to whom we are in some way accountable, such as managers and executives up the chain of command, but also, notably, investors. We also make these kinds of statements to peers and subordinates, but somehow I’ve found that the most chaotic and damaging effects of misunderstandings about what something really meant tend to happen when communicating upward in a power relationship. Consequently, reinforcing a clear understanding of these distinctions has become part of my standard routine for breaking in new bosses.
The distinctions are subtle, but important:
- Plans are about intention
- Predictions are about expectation
- Promises are about commitment
A plan is a prospective guide to action. A plan can be wrong (moreover, it can be known to be wrong) and yet be still useful. A plan is often an approximation or even a wild guess. However, if you are in a high state of ignorance and yet trying to take purposeful action, you have to start somewhere. As George Patton famously said, “A good plan, violently executed now, is better than a perfect plan next week.” Plans can readily change, because over time you learn things, particularly as a side effect of trying to execute the plan itself. In fact, in my line of work, if your plans aren’t changing relatively frequently you’re probably doing something wrong. Plans typically concern matters that are within your own sphere of control: “first I will do this, then I will do that”.
A prediction is declaration about what you think will happen. A prediction may very well encompass elements that are beyond your control. A prediction will often incorporate, if only implicitly, some model or theory or idea you have about how some part of the world works. When making a prediction, you are offering somebody else the benefit of your knowledge and analysis, so it can be beneficial to articulate your reasons for believing as you do. Like plans, predictions can change, but the reasons for change are different: a prediction can change if external facts change, or if you discover some shortcoming in your analysis. Thus it may also be important to be explicit and articulate when you change a prediction: explain why. Unlike a plan, a prediction that is just a wild guess is largely worthless, though a prediction that is the product of an inarticulable intuition may still be useful (but if so, in some sense it’s not really a wild guess — though it’s a valuable and rare skill to be able to reliably distinguish the times you are going with your gut from the times you are just stabbing in the dark).
A promise is a statement that you grant other people the right to treat as a fact that they can rely on, as they figure out their own actions and make plans, predictions, and promises of their own. A promise is a positive assertion that you will or will not do something specific. A promise is not something that generally changes; a promise is either kept or not kept. A change in circumstances may render a promise unkeepable or inappropriate, however. People put a lot of moral weight on promises, because accepting a promise requires trust. Because trust is involved, a broken promise can have emotional and organizational consequences that go beyond the direct practical effects of whatever contrary thing was or was not done. I could go on at length about the moral and emotional dimensions, but it would be a digression right now. The short version is: promises carry a lot of baggage.
On their face, these three kinds of things are all simply declarations about the future, and there’s nothing innate that necessarily marks which of these a given statement is: “I will mow the lawn tomorrow” could legitimately be taken as any one of the three. The differences have to do not with the form of the statement but with the intent. The reason the distinctions remain important, however, is because serious trouble can result when somebody says something intended as one of these categories, and somebody else interprets it as one of the others. The reasons for this sort of misinterpretation are varied and probably infinite: the person who said it was unclear what they meant, the person who heard it wasn’t paying attention, or misunderstood, or had different background assumptions, or was simply clueless. Sometimes the misinterpretation is deliberate and willful; this is especially destructive.
These categories are not pure. That is, a single statement is not necessarily 100% one of these things and 0% either of the others. A statement can be a mixture. However, having the parties at both ends of the communication be clear on what was intended is still essential.
There are many different ways trouble can result from interpreting a statement of one of these types as one of the others.
Treating a plan as if it were a prediction invites confusion and mayhem if the plan changes. The normal evolution of a project can be seen as evidence of problems where none actually exist: “You said you were going to do A and instead you did B. Why did you say you were going to do A? Do you really know what you are doing? Please explain.” A lot of time and energy can be dissipated accounting for changes to people for whom the changes weren’t actually important.
During the last year of the Habitat project, we reached the point were the product was fundamentally complete but it had a lot of bugs. The bug list became our main planning tool: each bug was assigned a priority and a rough time estimate, and the bug list was the thing that each developer looked to to decide what to do next. I call it a bug list, but not everything on it was, strictly speaking, a bug. Some things were tasks that we’d like to get done that needed to be balanced against the debugging work, and other things were just stuff that could be made better if we spent the time or resources. Since the world is constantly changing and we are constantly learning, a fairly common pattern was for a task to be identified and put on the list, and then gradually drift into some form of irrelevance as the shape of the system evolved or operational experience gave us feedback about what was really important. This kind of drift and accompanying deprioritization is a process that every developer should be familiar with.
Perversely, we found ourselves keeping multiple uncoordinated bug lists. As the project matured we acquired a product manager, who was a well intentioned but ultimately useless detail freak. In an attempt to track the status of the project, in hopes of answering management’s eternal question, “when is it going to be done?”, she’d convene status meetings wherein she’d try to use the bug list as checklist. Every couple of days we’d spend several hours going through these items, and all the dross that we’d been ignoring because it was irrelevant or pointless became a topic for discussion, and “never mind that” was never an acceptable way to dispose of these items. Her reasoning was that if something had been important enough to get put on the list, it shouldn’t be taken off without due consideration. Since she wasn’t the person doing the work and so didn’t understand a lot of the particulars, everything had to be argued and debated and explained, wasting many hours of time. Plus, she’d be adding up all the time estimates for these random and vague things and freaking out because the total was wildly unreasonable — never mind that the estimates were engineers’ guesses to begin with and many of these tasks would never be done anyway. And on top of all that, a lot of these status meetings were teleconferences with our partners at QuantumLink, where each of these irrelevant items got unfolded into even more useless discussion and became the basis for lots of interorganizational dispute. So we found ourselves developing the defensive habit of keeping private todo lists of tasks we’d identified that we didn’t want to have to spend hours debating, and everybody made up their own plan.
The consequence of all of this was that a whole lot of planning activity was taking place off the books, so when the work got done it meant that lots of resources were spent on things that never showed up in the official project plan and could not be accounted for. It also meant that each of us had much fuzzier than necessary picture of what the others were doing, and management had a worse picture than that.
Nearly every experienced developer I know has his or her own variation of this story. Many of us have several.
A plan that is treated as a promise is even worse than one treated as a prediction. A normal change of plan can become an invitation to recrimination or outright hostility or even punishment. Plans treated as promises are at the root of many of the most awful cases of organization dysfunction I’ve ever experienced.
One of the projects I worked on at Yahoo! (to protect the guilty I will refrain from naming names) actually kept two schedules: the official schedule, for showing to upper management (the promise), and the real schedule, for day to day use by the people doing the work (the plan). As the project evolved, these two diverged ever more sharply, until the picture that upper management was getting became a complete and utter fantasy. At one level, the problem was that the person running the project was a craven coward, afraid of telling the truth to his superiors because he knew they wouldn’t like it (the real schedule said that things were going to take a lot longer than the Potemkin schedule said — funny how it never seems to go the other way). But at another level, the deeper problem was that the higher echelon people persisted in treating any forward looking statement by their subordinates as a promise, which made planning impossible.
Treating a prediction as a promise holds someone responsible for the consequences of their analysis rather than for the quality of the analysis itself. Even if someone has some control over whether a prediction comes true or not, the mere act of making a prediction should not carry with it the obligation to intervene to ensure the outcome. Many predictions are conditional, statements of the form “if A happens then B will happen”; this does not mean that someone who says this is now committed to making A happen. Indeed, as with plans, changes in circumstances can render a prediction wrong or irrelevant. It may be more constructive to adapt to the changed reality than to try to bend reality just to preserve the prediction.
Treating a prediction as a promise often leads to people being held responsible for things they have no control over. Putting people in this sort of bind is a classic cause of various forms of mental illness. Aside from being basically useless and stupid, this is great a way to make people hate you, and you’d deserve it. Nevertheless, how many of us have experienced a boss refusing to hear that something can’t be done, even when it really couldn’t?
Treating a prediction as a promise abdicates responsibility. If you are obligated to produce some outcome and fail because some prediction you relied on turns out to have been wrong, it is still your fault. It was you who chose to rely on the prediction. Government and big business both do this all the time, trying to duck accountability for mismanagement or malfeasance by pointing at external estimates or projections gone wrong (indeed, at times it seems like the Congressional Budget Office was established principally to enable politicians to use this particular dodge).
The failure modes just discussed are the worst, because each, in one form or another, imputes causality that isn’t really there. The other possible category confusions can still be disruptive, however, by jumbling the mental models people use to make sense of the world.
If you treat someone’s promise or prediction as a plan, it means you are pretending they have a plan when they might not. You are confusing ends with means. Sometimes, of course, you don’t care what their plan is, and sometimes it’s none of your business anyway, but in such cases you should know that you are banking on the quality of their analysis or of their commitment, and not on a fantasy model of what they are doing.
If you treat someone’s promise as a prediction, you risk using the wrong grounds to assess the validity of their statement. You consider the trustworthiness of a prediction by looking at the predictor’s knowledge and analytic ability, whereas a promise is evaluated by looking at the promisor’s incentives and their ability to execute the relevant tasks. These two pathways to assessment are wildly different, and so if you use one when you should use the other you are in danger of getting the wrong answer.
There are already plenty enough ways for organizational relationships to go off the rails without adding the various nasty species of communications failures I’ve described here. However, I don’t think it’s sufficient to just exhort everyone to try to be clearer. Managers, in particular, need to be aware of these failure modes and press for clarity when somebody says something forward looking and the category it belongs in is uncertain. Because humans tend to like certitude, many managers have a bias towards interpreting the things people say as constraining the future more than they actually do. If they do this a lot, it teaches their subordinates to be stingy with their knowledge, timid in their public outlook, and even sometimes to lie defensively. All of these things are corrosive to success.
March 23, 2011
SM Pioneers: Farmer & Morningstar – How Gamers Made us More Social
Shel Israel has just posted @Global Neighbourhoods the latest in his series of posts from his upcoming book Pioneers of Social Media – which includes an interview with us about our contributions over the last 30+ years…
How Gamers Made us More Social
Many of us often overlook the role that games have played in creating social media. They provided much of the technology that we use today, not to mention a certain attitude. Of greatest importance, is that it was on games that people started socializing with each other in large numbers, online and in public. It was in games that people started to self-organize to get complex jobs accomplished.
We had people meeting and sharing and talking and performing tasks several years before we even had the Worldwide Web.
We’re honored to be amongst those highlighted. Shel says about 100 folks will be included. There won’t be enough pages, but we eagerly look forward to the result none-the-less.
January 15, 2011
Requiem for Blue Mars
Another virtual world startup (Blue Mars) is dying. At The Andromeda Media Group Blog Will Burns [Aeonix Aeon] writes:
Looking Back at the Future
The really interesting part about all of this is that in order to see the future of Avatar Reality, and subsequently Blue Mars (or any virtual environment today), we need not look into the future but instead look to the past…
[many interesting insights about 1990s era worlds]
In 1990, the solution was given by two people to all of this madness. Chip Morningstar and F. Randall Farmer, authors of Lessons Learned From Lucasfilm’s Habitat. Strangely enough I had asked Mr Farmer about Linden Lab and he informed me that he was actually called in as a consultant in the early days, and not surprisingly, ignored.
That’s a bit of a harsh summary, but more than five years ago I did write The Business of Social Avatar Virtual Worlds: Or, why I really like Second Life, even if their business is most likely doomed. Clearly I wasn’t 100% right about them – they found a business model that at least got them to cover their run-rate. But many of the things in there may to apply to Blue Mars…